
In November 2025, we announced that Eigen AI's serving APIs were officially listed on Artificial Analysis with record-breaking throughput for our first set of models. In February 2026, we expanded that leadership to 11 models. Today, we're proud to share that Eigen AI now holds the #1 output speed across 25 of the most widely used open-source models tracked by Artificial Analysis — more than doubling our footprint in just six weeks.
This milestone reflects the depth and breadth of EigenInference’s full-stack optimization across every major model family, architecture type, and workload category in the open-source ecosystem.
25 Models, One Consistent Result: Fastest in Class
Our infrastructure delivers peak output throughput (tokens/sec) across a massive diversity of architectures — from dense language models and Mixture-of-Experts (MoE) to vision-language models, reasoning specialists, and coding-optimized variants. On Artificial Analysis, Eigen AI consistently ranks as the #1 GPU-based provider* for all 25 models listed below.
| Model | Eigen Output Speed (tokens/sec) | Workload |
|---|---|---|
| GPT-OSS-120B (high) | 913 | General |
| GPT-OSS-120B (low) | 738 | General |
| Kimi K2.5 (Non-Reasoning) | 401 | General |
| GLM-5 (Non-reasoning) | 200 | General |
| DeepSeek V3.2 (Reasoning) | 80 | Reasoning |
| DeepSeek V3.1 (Reasoning) | 279 | Reasoning |
| DeepSeek V3.1 Terminus (Reasoning) | 143 | Reasoning |
| DeepSeek V3.1 Terminus | 140 | General |
| Llama-4 Maverick | 338 | General |
| Llama-4 Scout | 506 (1k coding) | Coding |
| Llama-3.3-70B | 294 | General |
| Llama-3.1-8B | 764 (1k coding) | Coding |
| Qwen3.5 397B A17B (Reasoning) | 142 | Reasoning |
| Qwen3.5 397B A17B (Non-reasoning) | 149 | General |
| Qwen3 Coder 480B | 250 (10k general) / 374 (1k coding) | General / Coding |
| Qwen3 235B A22B 2507 (Reasoning) | 178 | Reasoning |
| Qwen3 235B A22B 2507 Instruct | 320 | General |
| Qwen3 Next 80B A3B (Reasoning) | 322 | Reasoning |
| Qwen3-VL 235B A22B | 81 | Vision-Language |
| Qwen3-VL 30B A3B (Reasoning) | 255 | Vision-Language / Reasoning |
| Qwen3-VL 30B A3B (Non-reasoning) | 262 | Vision-Language |
| Qwen3 30B A3B (Reasoning) | 259 | Reasoning |
| Qwen3 30B A3B (Non-reasoning) | 269 | General |
| Qwen3 8B (Reasoning) | 360 | General |
| Qwen3 8B (Non-reasoning) | 384 | General |
- #1 speed across GPU providers, excluding ASIC providers, under default Artificial Analysis settings (10K input) unless noted otherwise. Benchmarks as of March 15, 2026.
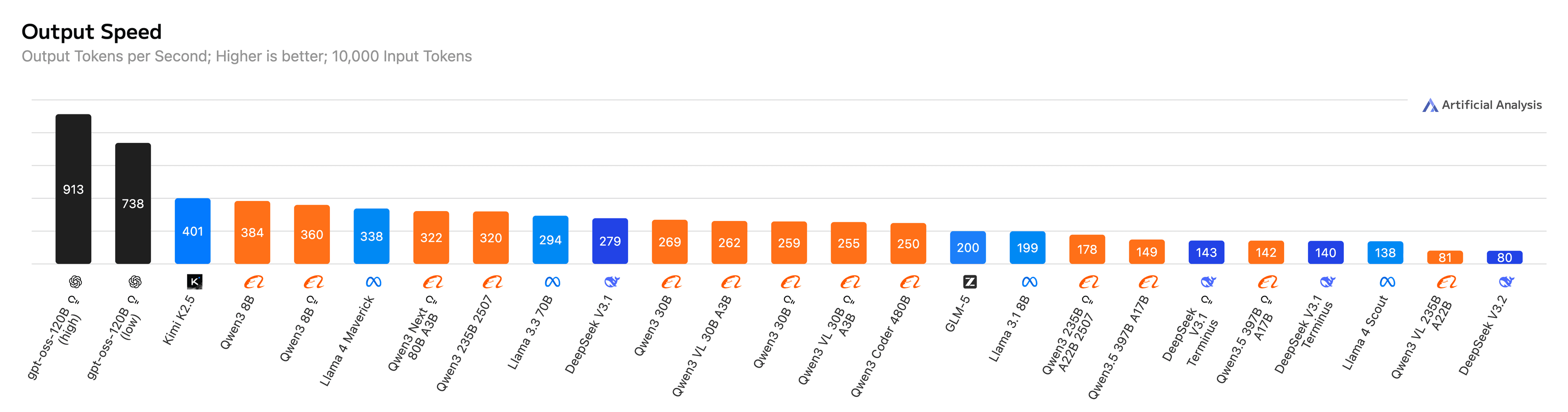
Figure 1: Eigen AI ranks as the #1 GPU-based provider for all 25 models on Artificial Analysis.
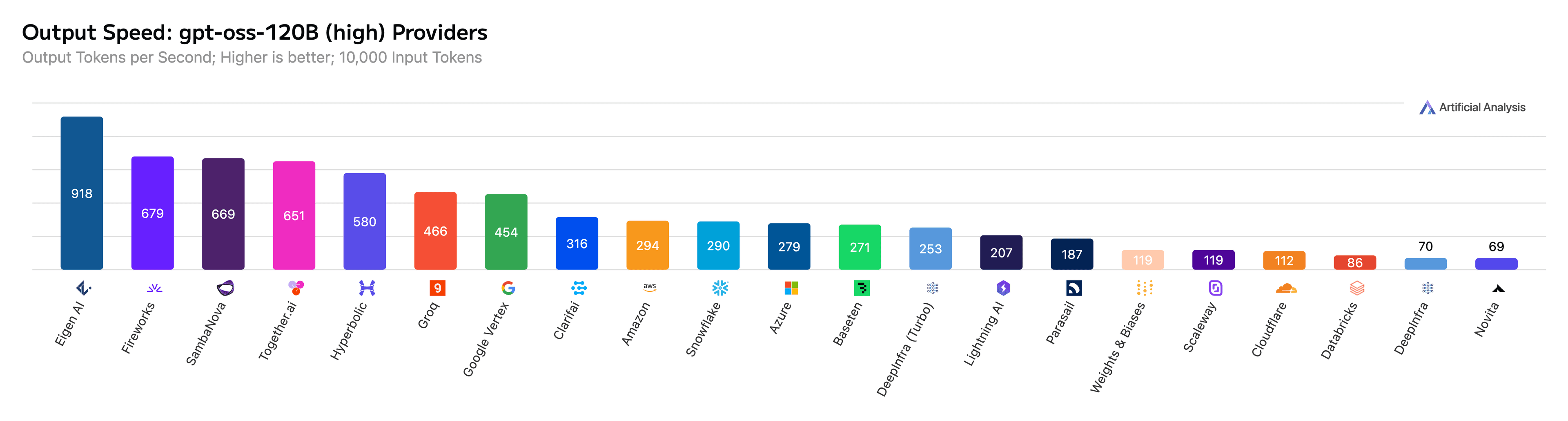
Figure 2: Eigen AI achieves 918 output tokens per second for GPT-OSS-120B on Artificial Analysis.
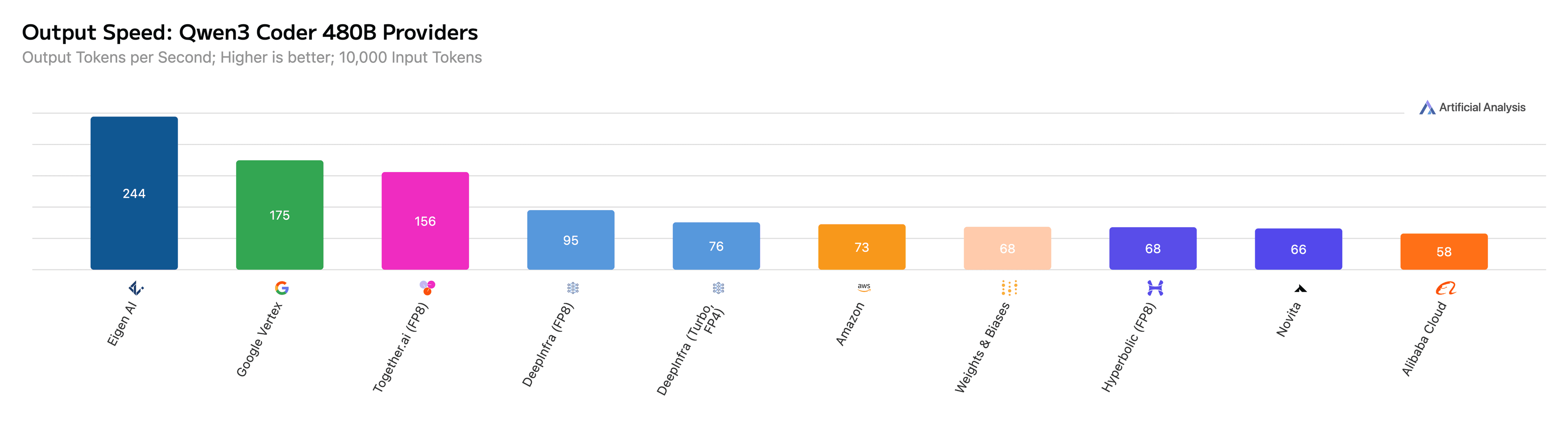
Figure 3: Eigen AI achieves 244 output tokens per second for Qwen3 Coder 480B on Artificial Analysis.
From 11 to 25: What Changed
The rapid expansion from 11 to 25 #1 rankings wasn’t just about adding more models to our catalog — it reflects continued investment across the full EigenInference optimization stack:
Broader architecture coverage. We extended our optimizations to the latest model releases, including DeepSeek V3.2, GLM-5, Kimi-K2.5, MiniMax-M2.5, Qwen3.5, Qwen3, and the Llama family. Each architecture brings unique challenges — new attention mechanisms, larger expert counts, hybrid reasoning modes — and our team has delivered leading throughput on every one of them.
Deeper MoE optimization. Mixture-of-Experts models like Qwen3 Coder 480B, Qwen3.5 397B, and DeepSeek V3.2 require careful expert routing, GPU scheduling, and KV cache and memory management to perform well in production. Our custom CUDA and Triton kernels, combined with advanced speculative decoding and quantization, deliver consistent speed advantages on these architectures.
Reasoning and multi-modal breadth. We now hold #1 rankings across general, reasoning, coding, and vision-language workloads — demonstrating that EigenInference is not tuned for a single modality but optimized across the full spectrum of production use cases.
The EigenInference Engine: Why We’re Consistently #1
Our performance leadership is the result of deep, full-stack optimization at every layer. The key pillars of the EigenInference engine include:
Advanced Quantization. Our pioneering NVFP4 and FP3 quantization methods, combined with system-level optimizations, match or exceed FP16/BF16 accuracy while delivering the throughput benefits of low-precision compute. This includes high-fidelity PTQ (Post-Training Quantization) and QAT (Quantization-Aware Training).
Speculative Decoding & Custom Kernels. We leverage state-of-the-art auto-regressive methods (such as Eagle-3) and diffusion-based methods (such as DFlash) to predict future tokens and accelerate generation. Our hand-optimized CUDA and Triton kernels for GEMM and Attention are purpose-built for NVFP4, extracting maximum performance from the hardware.
KV Cache Optimization. Long-context generation is often bottlenecked by memory bandwidth. We address this with NVFP4 KV cache quantization and intelligent cache pruning, enabling larger batch sizes and longer sequences without sacrificing speed.
Multi-Granular Sparsity. EigenInference employs a multi-level sparsity strategy — architectural sparsity (pruning channels, heads, experts, and layers), hardware-aware N:M weight sparsity for Tensor Core acceleration, and dynamic token-level sparsity (token dropping and merging) to reduce the quadratic cost of attention in real-time.
System-Level Runtime Optimizations. Continuous batching, parallel computing, graph capture, and CPU offloading ensure maximum resource utilization across every GPU cycle.
Production-Grade Reliability at Scale
Speed is only meaningful when it comes with stability. Every Eigen AI endpoint is backed by production-grade deployment infrastructure through EigenDeploy:
- Traffic-aware autoscaling that adjusts to real-time demand
- Hot restarts and multi-replica high availability to eliminate downtime
- Token-level traces and real-time metrics for full observability
- Flexible deployment across serverless, on-demand, and dedicated instances
What’s Next
We’re continuing to expand our model coverage and deepen our optimization stack. As new frontier open models are released — with increasingly complex architectures, larger expert counts, and multi-modal capabilities — Eigen AI will be there on day one with production-ready, #1-speed implementations.
Experience top-tier inference for your own applications.
Artificial Efficient Intelligence — AGI Tomorrow, AEI Today.