
Reliable Post-Training for Interactive Tool-Using Agents: Self-Evolving Data + Verifiable Rewards
TL;DR
Interactive tool-agent post-training is unstable because user simulation noise corrupts delayed-reward learning (Telecom: 85.4% → 75.6% without a proper user simulator).
We propose EigenData + verifier-based RL, where EigenData self-evolves multi-turn trajectories and synthesizes executable verifiers, enabling user–model SFT followed by GRPO training.
On τ²-bench, this yields strong improvements (Airline 58.0% → 73.0% pass¹; Telecom 53.7% → 98.3% pass¹) and ablations confirm the gains are causal.
The results are available on arXiv, and the code and data will be released soon.
Why Interactive Tool-Using Agent Post-Training Is Unstable
As language models move from static QA to real-world deployment, agents are increasingly required to interact over multiple turns with both users and external tools.
Unlike single-turn tool use, interactive agents face three structural challenges:
- Information asymmetry — Critical constraints and preferences are revealed incrementally through dialogue.
- Delayed and sparse rewards — Correctness can only be evaluated after a full interaction trajectory completes.
- User-driven stochasticity — Training requires a user simulator, whose behavior directly affects rollout outcomes.
In practice, these factors make post-training extremely fragile.
We observe that naïvely applying RL to interactive agents often produces negative returns: even when the agent behaves correctly, unstable user behavior can lead to task failure and zero reward.
On τ²-bench (Telecom domain), starting from a strong SFT checkpoint:
- pass¹ = 85.4% before RL
- RL without stabilizing user behavior drops performance to 75.6%
This degradation is not due to policy regression—but corrupted learning signals.
Bottlenecks: Why Existing Data + RL Pipelines Do Not Scale
Two common approaches dominate current practice, both with critical limitations.
Manual Data Curation
- Human-designed workflows and prompts
- High quality but non-scalable
- Hard to cover long-tail interaction patterns
Static Synthetic Data Without Verifiable Rewards
- Automated generation pipelines
- Often produce infeasible tasks, shallow interactions, or unverifiable outcomes
- Primarily suitable for SFT, not RL
Most importantly, data generation and reward definition are treated as separate problems, leading to misalignment between training signals and actual task success.
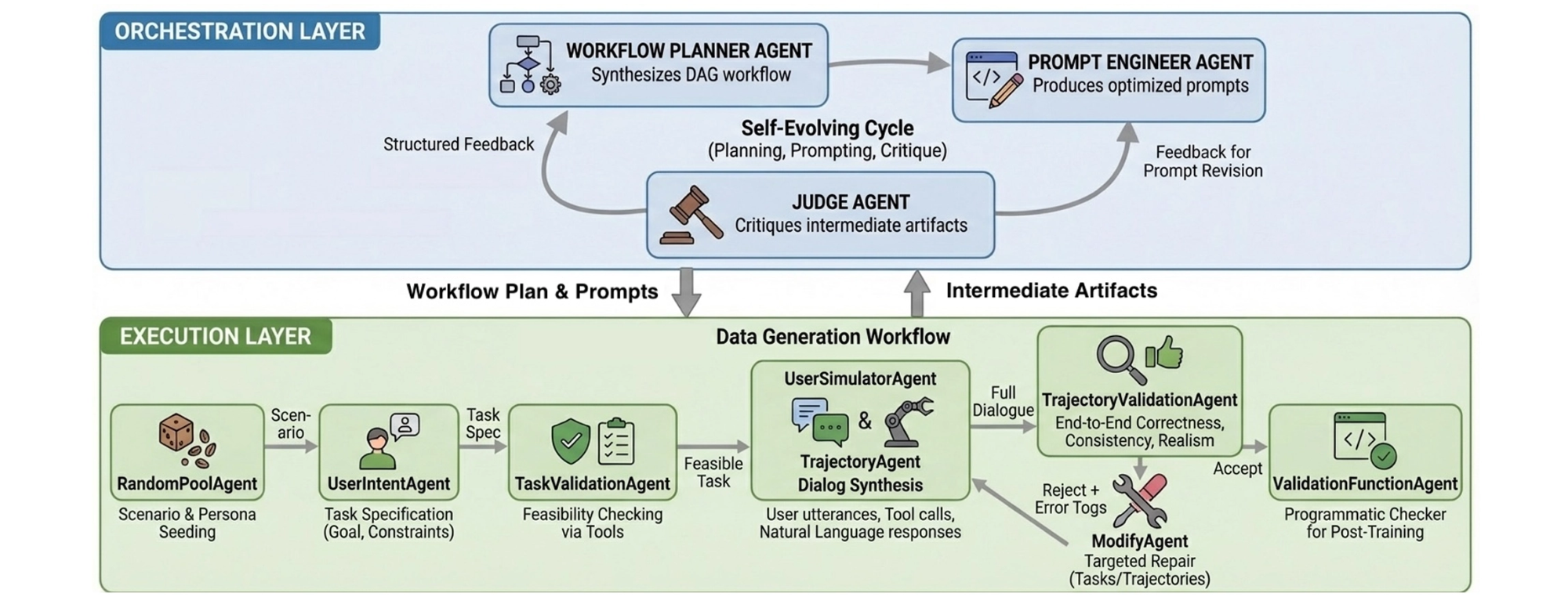
Solution: EigenData (Self-Evolving Data) + Verifier-Based RL
To address these issues, we propose a closed-loop post-training system that jointly designs:
- Interaction data
- Reward signals
- Reinforcement learning dynamics
At its core are two components:
- EigenData — a self-evolving agentic data engine
- Verifier-based RL — reinforcement learning grounded in executable outcomes
Method: EigenData for Self-Evolving, Verifiable Interaction Data
EigenData is a hierarchical multi-agent system that autonomously generates and improves multi-turn tool-use trajectories.
What Each Training Instance Contains (Dialogue + Tools + Verifier)
Each generated training instance includes:
- A validated task specification
- A full multi-turn dialogue
- Grounded tool call traces
- A per-instance executable verification function
The system is self-evolving:
- Failed or low-quality instances are critiqued by a Judge agent
- Feedback updates both prompts and workflows
- Generation quality improves across iterations—without human intervention
After evolution, we observe:
- Task infeasibility rates below 5%
- High tool-call validity enforced by schema-level checks
- Long-horizon trajectories requiring 5–15 tool calls per task
Why It Works: Aligning Data Generation, Reward Definition, and Validation
By generating verification functions alongside data, reward computation becomes:
- Deterministic
- Execution-grounded
- Robust to paraphrasing or surface-level hacks
This makes the data directly usable for reinforcement learning, not just SFT.
Stabilizing RL Under Interaction Noise
On top of EigenData, we apply a reinforcement learning recipe tailored for interactive agents:
- User model fine-tuning — User simulators are trained on EigenData-generated dialogues to reduce rollout variance.
- Group Relative Policy Optimization (GRPO) — Multiple trajectories per task are sampled, and advantages are computed relative to the group.
- Dynamic filtering — Tasks with no reward variance are excluded to prevent zero-signal updates.
This design isolates agent learning from user-side noise.

Experimental Validation
We evaluate our approach on τ²-bench, spanning Airline, Retail, and Telecom domains.
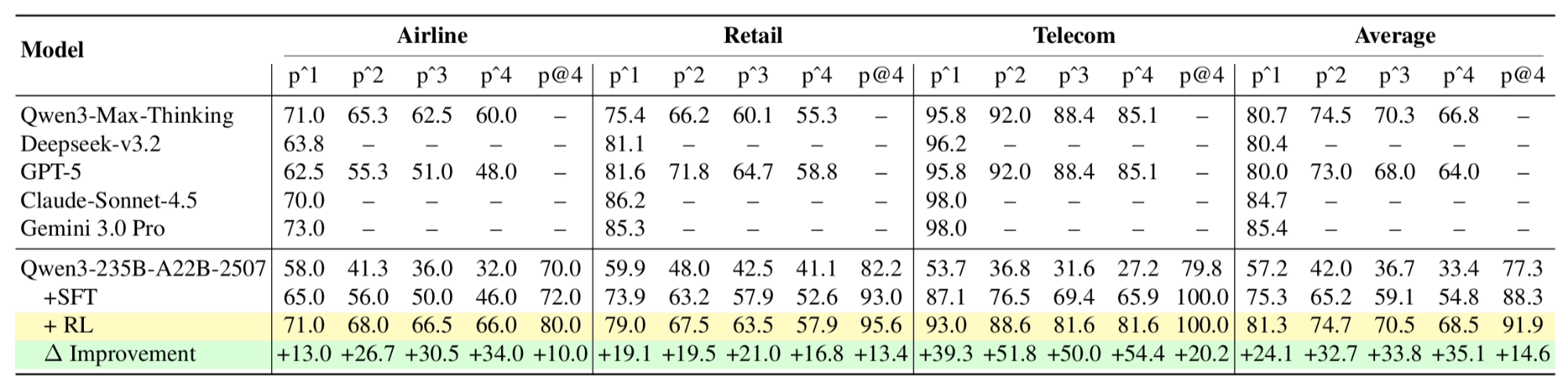
Main Results
On Qwen3-235B-A22B models:
- Airline: pass¹ improves from 58.0 → 73.0 after RL
- Telecom: pass¹ reaches 98.3%, exceeding Gemini 3.0 Pro and Claude Sonnet
- Mixed-domain training: average pass¹ = 81.3%, higher than GPT-5 (80.0%)
These results demonstrate that open-weight models trained with EigenData can match or exceed frontier systems.
Ablation Studies: Verifying the Claims
To ensure gains are not incidental, we perform systematic ablations.
Both validation and self-evolution are necessary.
User Model Ablation (Telecom, RL)
- RL with base user model: 75.6% pass¹
- RL with fine-tuned user model: 95.6% pass¹
A ~20-point gap confirms that user stability is a first-order factor in interactive RL.
What This Changes
Our results suggest a shift in how interactive agents should be trained:
- The bottleneck is learning signal quality, not model size
- Data, rewards, and RL must be designed as one system
- Self-evolving synthetic data can replace manual pipelines at scale
EigenData is not a dataset—it is a training infrastructure.
Interactive agents fail not because they cannot reason, but because they cannot learn reliably from interaction.
By combining self-evolving data generation with verifiable-reward RL, Eigen AI provides a scalable path to:
- Stable long-horizon learning
- Reliable tool execution
- Open-weight agent competitiveness
As agents become more autonomous, systems, not prompts, will define their limits.