
Eigen AI Delivers Industry-Leading Speed Across 11 Premier Models on Artificial Analysis
Back in November 2025, our blog post unveiled that Eigen AI’s serving APIs were officially listed on Artificial Analysis, showcasing record-breaking throughput for our first set of models. Today, we are proud to announce that we have expanded this performance leadership across 11 of the most prominent models in the industry, consistently securing top-tier rankings for speed, latency, and efficiency.
A Leader Across the Board: The Benchmarks
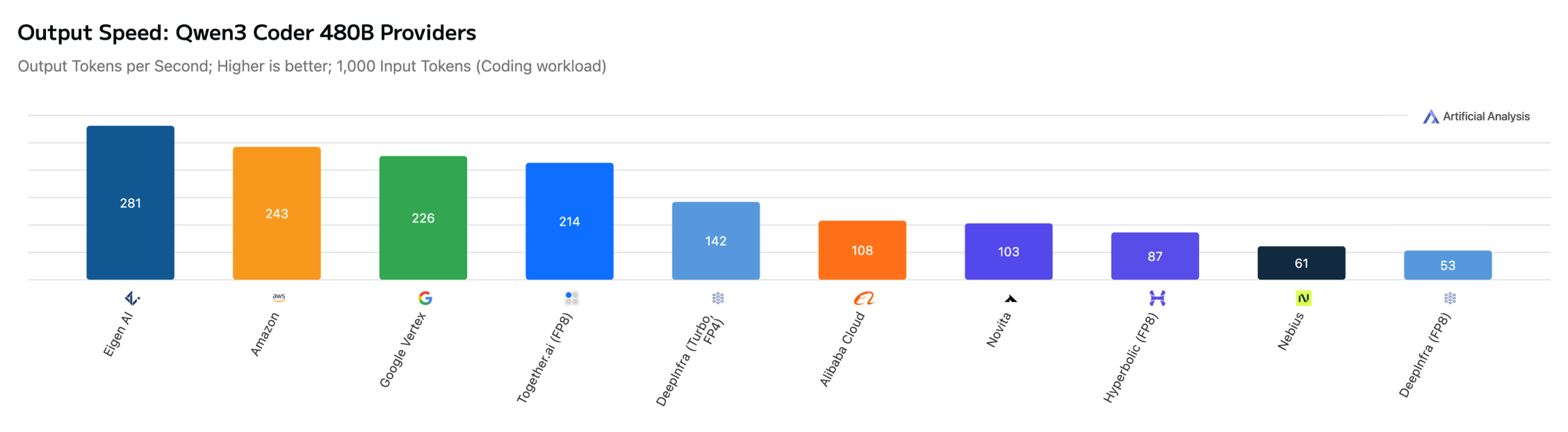
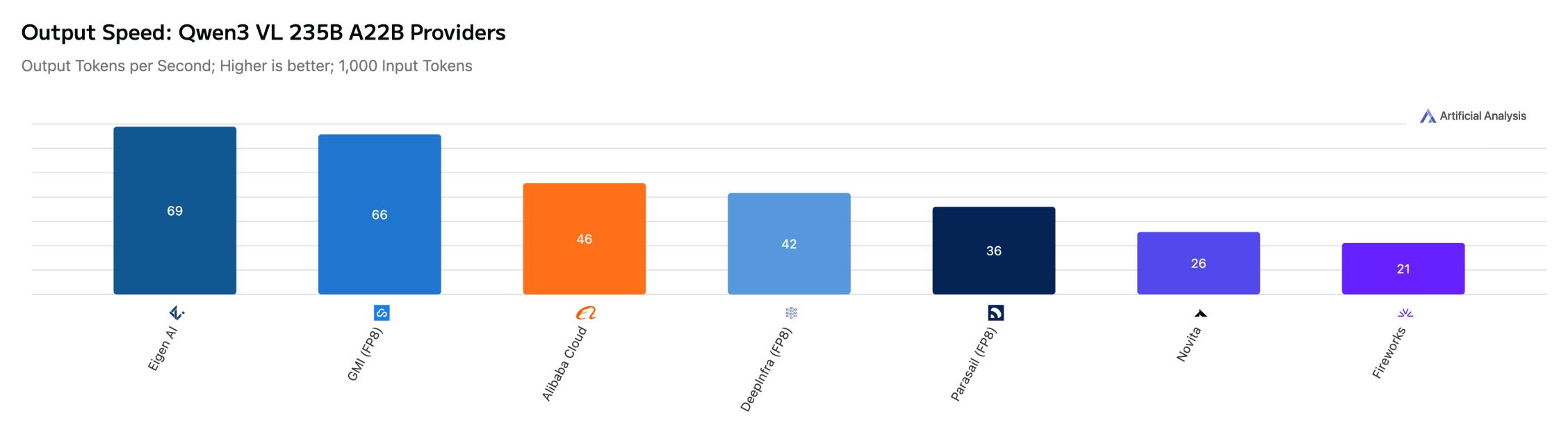
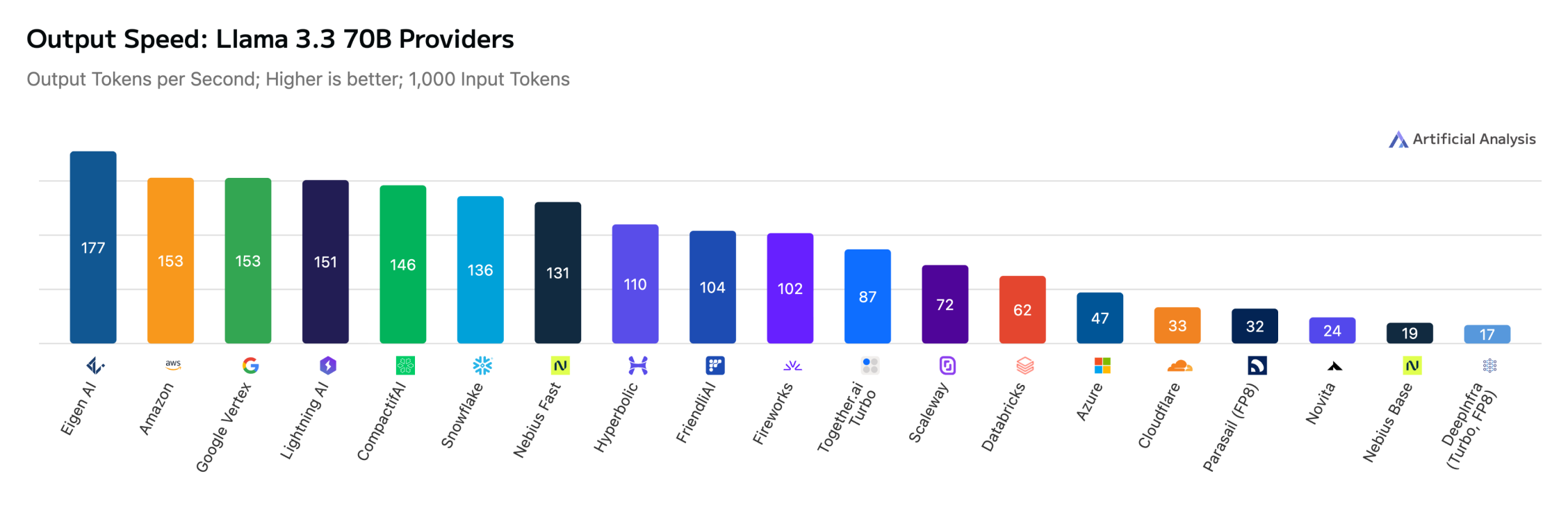
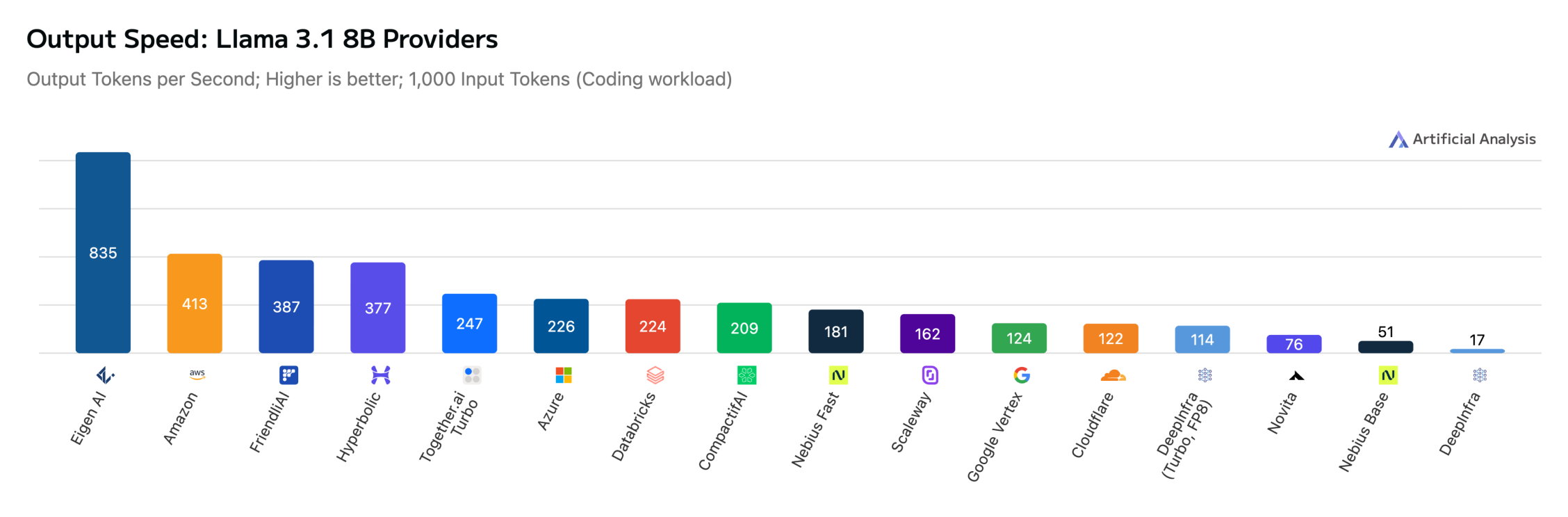
Our infrastructure is optimized to deliver peak output throughput (tokens/sec) and ultra-low TTFT (Time to First Token) across a diverse range of architectures. On Artificial Analysis, Eigen AI consistently emerges as a top-ranked provider for 11 models with a massive variety of architectures, from pure-text language models, high-density coding models to the latest vision-language specialists:
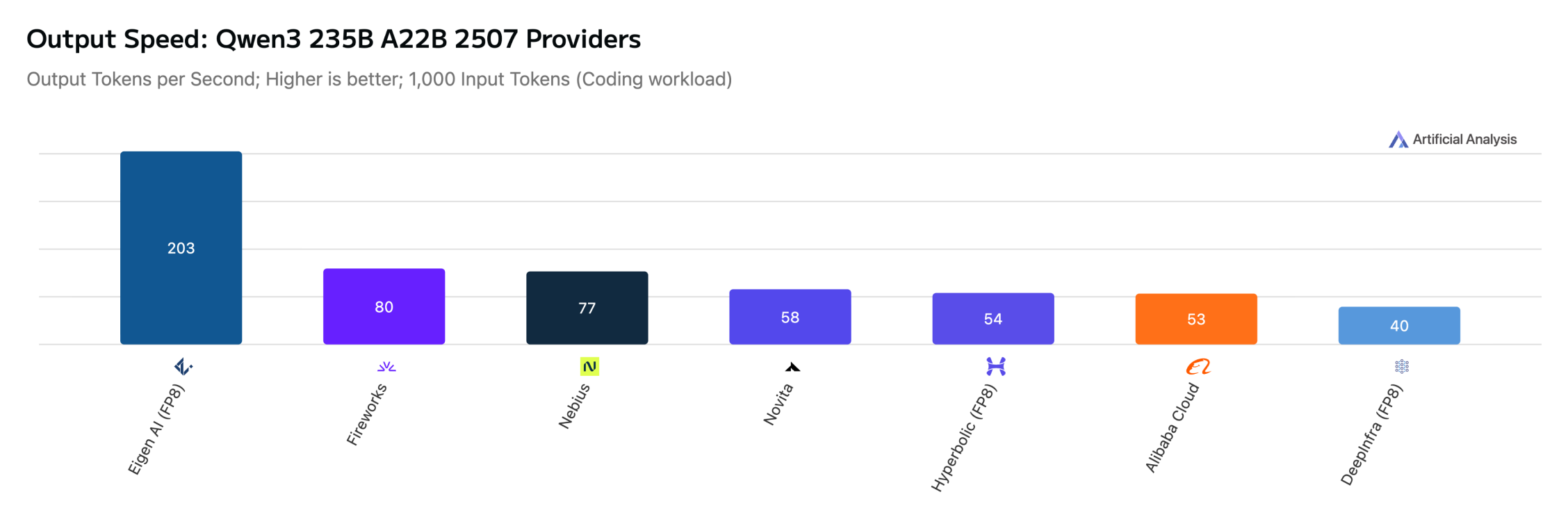
Qwen3 235B A22B 2507 (Reasoning)
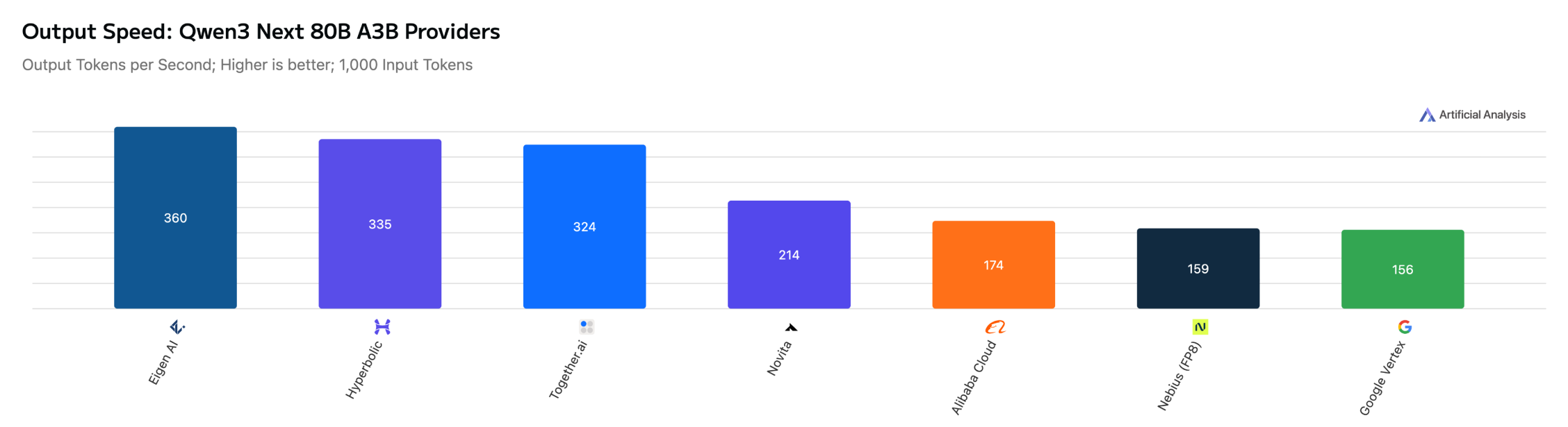
Qwen3 Next 80B A3B (Reasoning)
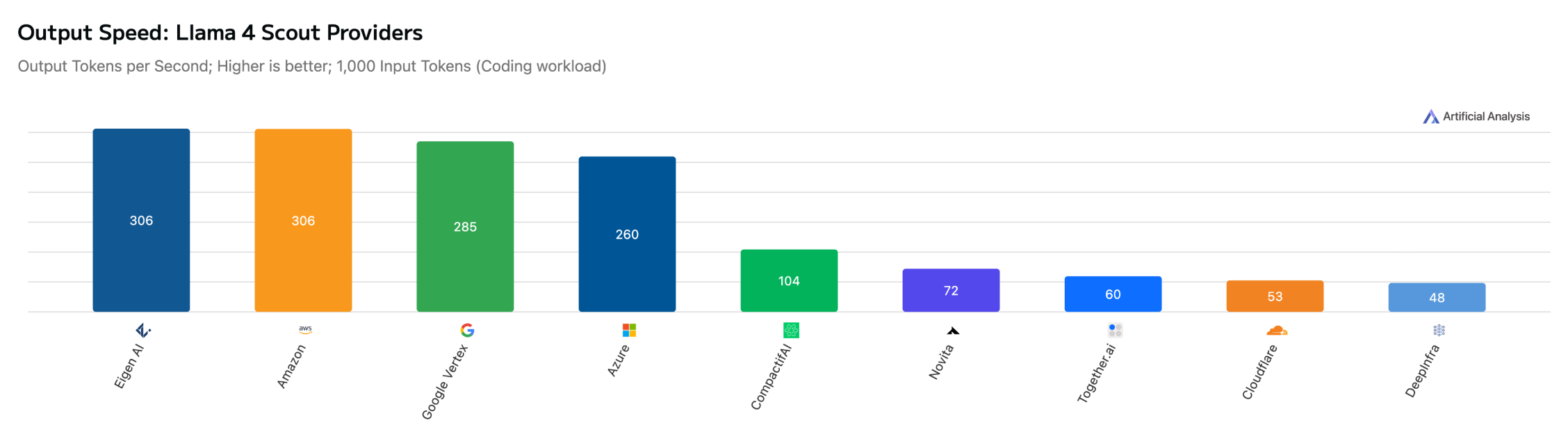
DeepSeek V3.1 Terminus (Non-reasoning)
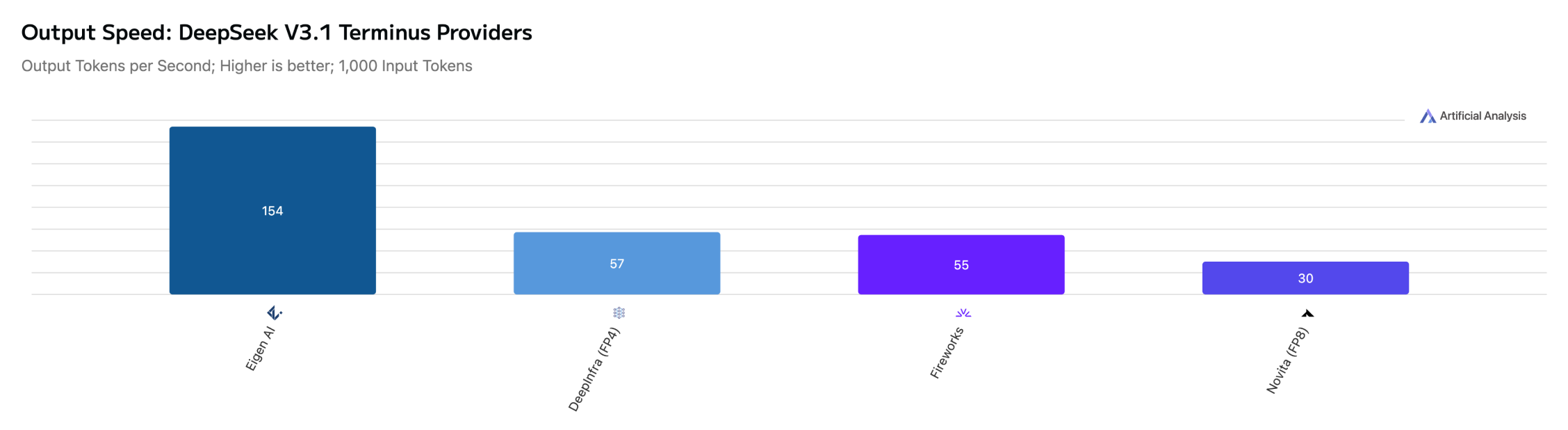
DeepSeek V3.1 Terminus (Reasoning)
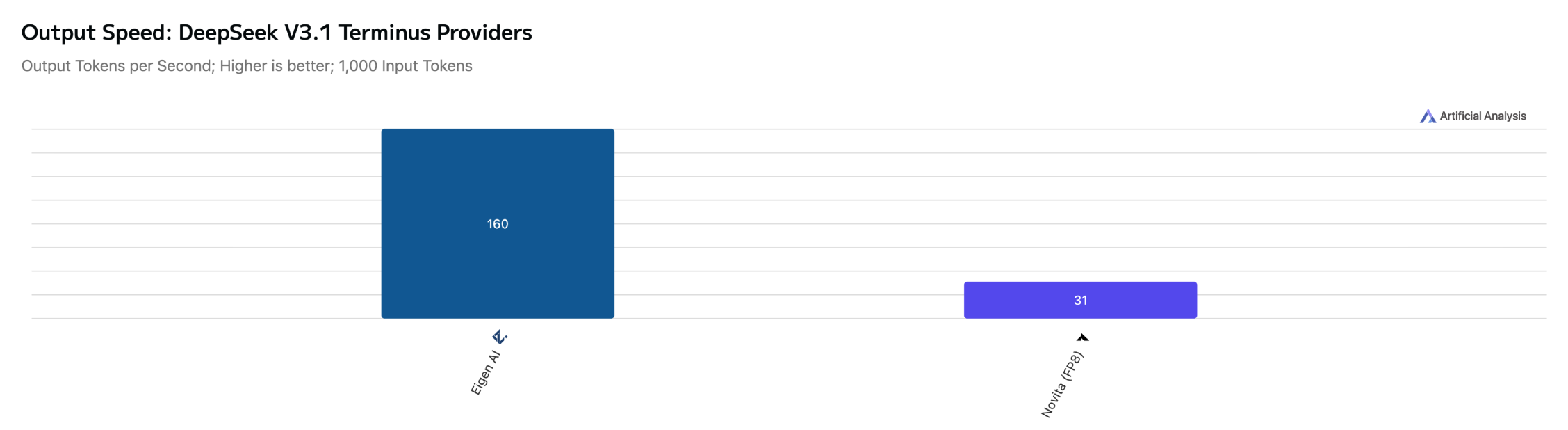
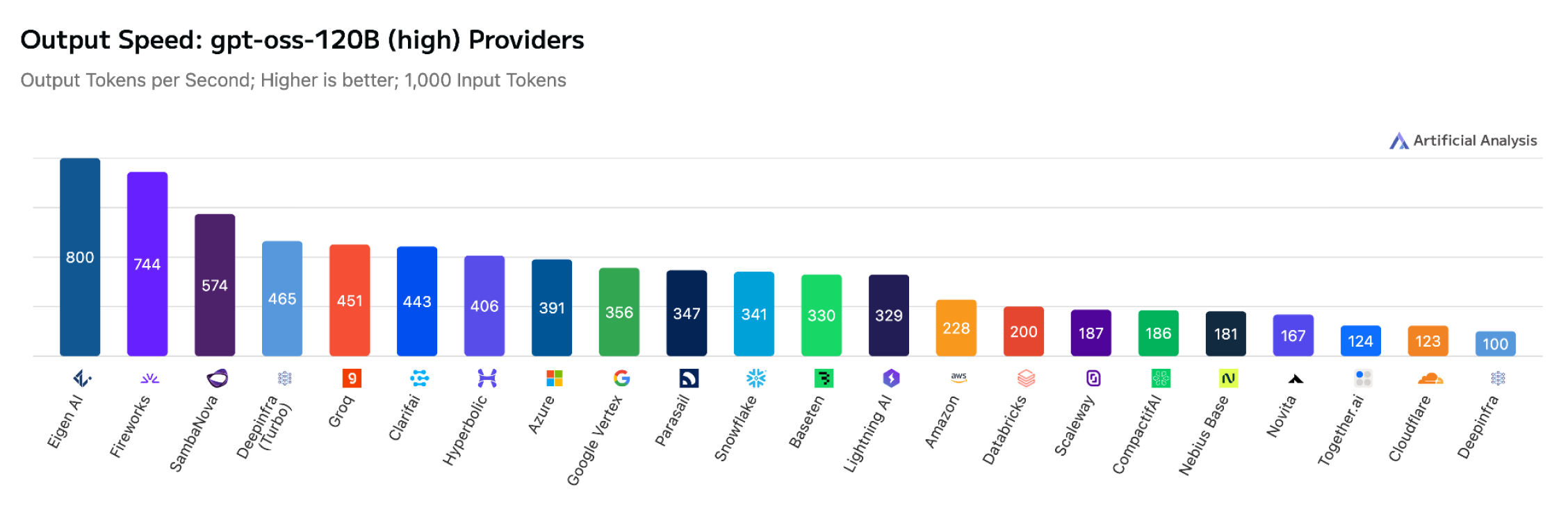
Why Speed and Stability are Non-Negotiable
In the world of model serving, speed is the engine that drives your Service Level Agreement (SLA). Low latency ensures a seamless user experience, while high throughput determines your cost efficiency. However, speed is meaningless if it lacks stability, reliability, and robustness.
At Eigen AI, we provide more than just raw tokens-per-second. We guarantee our customers the best inference speed in the industry coupled with production-grade reliability, ensuring your agents and applications stay responsive even under heavy, unpredictable loads.
The EigenInference Engine: The Tech Behind the Speed
Our performance isn't magic—it’s the result of deep, full-stack optimization across every layer of the inference engine.
1. Advanced Quantization: Precision Without Compromise
We’ve pushed the boundaries of what low-bit precision can achieve.
- NVFP4 & FP3 Innovation: We have pioneered a brand new NVFP4 (and even FP3) quantization method that, when combined with our system-level optimizations, can match or even exceed FP16/BF16 accuracy. * The Result: You get the performance and throughput of low-precision compute without the traditional accuracy trade-off. Please stay tuned—we’ll release the paper and blog post soon!
- Includes high-fidelity PTQ (Post-Training Quantization) and QAT (Quantization-Aware Training).
2. Speculative Decoding & Customized High-Performance Kernels
- State-of-the-art Speculation: We utilize auto-regressive methods (like Eagle-3) and diffusion-based methods (like DFlash) to "guess" future tokens, drastically enhance the overall speed and throughput. Find more details in our blog post on speculative decoding.
- Custom CUDA/Triton Kernels: Our hand-optimized kernels for GEMM and Attention are purpose-built for NVFP4, squeezing every teraflop out of the Blackwell silicon.
3. Distillation: The Intelligence Recovery Engine
We treat distillation as a core component of the optimization pipeline, not an afterthought.
- Pruning w/ Distillation: We utilize a "one-two punch": first pruning the model to remove redundant parameters, then using distillation to recover any lost accuracy.
- QAD (Quantization-Aware Distillation): We use student-teacher dynamics to ensure that even at ultra-low bit-widths, the model retains the reasoning capabilities of its larger predecessors.
4. KV Cache Optimizations: Breaking the Memory Bottleneck
Long-context generation is often limited by memory bandwidth rather than compute. We solve this through:
- KV Cache NVFP4 Quantization: Drastically reducing the memory footprint of the KV cache to allow for larger batch sizes and longer sequences.
- KV Cache Pruning: Intelligently evicting less important tokens from the cache to maintain speed without sacrificing context awareness.
5. Multi-Granular Sparsity: Surgical Efficiency
Speed in modern inference is often a game of "doing less to achieve more." EigenInference employs a multi-level sparsity strategy:
- Architectural Sparsity: Pruning redundant **channels, heads,**experts and/or layers to simplify the computational graph.
- Hardware-Aware Weight Sparsity (N:M): Utilizing semi-structured patterns designed to leverage NVIDIA Tensor Cores for maximum acceleration.
- Dynamic & Token-Level Sparsity: Employing token dropping and token merging to reduce the sequence length L in real-time, effectively mitigating the O(L^2) cost of the attention mechanism.
6. System-Wise Runtime Optimizations
Speed is also a product of how we manage the hardware. Our stack includes continuous batching, parallel computing, graph capture, and CPU offloading to ensure 100% resource utilization.
Cross-Modality Leadership
Our acceleration isn't just for text. The Eigen stack delivers industry-leading performance across the entire multimodal spectrum:
- LLMs & VLMs for text and visual reasoning.
- Image & Video Generation for lightning-fast creative workflows. [Link]
- Audio (ASR and TTS) for real-time voice interactions. [Link]
Beyond Speed: Reliable GPU Serving
We provide the orchestration to match our inference speed. From Serverless endpoints that handle spiky traffic to Dedicated instances for high-volume, isolated workloads, Eigen AI ensures that "fast" is also "fail-safe."
- Traffic-Aware Autoscaling: Scale based on real-time demand.
- Hot Restarts & HA: Multi-replica high availability to eliminate downtime.
- Observability: Token-level traces and real-time metrics for full transparency.
- Deployment Flexibility: Whether you use serverless for spiky traffic or dedicated instances for steady-state workloads, you get the same elite performance.
Partner with Eigen AI—The New Standard in AI Performance
Eigen AI is defining the frontier of Artificial Efficient Intelligence. We provide the infrastructure that allows you to ship faster, scale wider, and maintain the most rigorous reliability standards in the industry.
Experience top-tier inference for your own applications.
Try our API at the Eigen AI Model Studio
Artificial Efficient Intelligence — AGI Tomorrow, AEI Today.