
Palo Alto, Calif., March 15, 2026 — Eigen AI and Nebius are partnering to bring faster, optimized open-source AI models to Token Factory, Nebius’s platform for running open models in production. As part of this collaboration, the two companies are co-developing optimized versions of leading open-source models and integrating them directly into Token Factory — giving developers immediate access to high-performance inference without building or maintaining their own optimization infrastructure.
The Challenge: Bridging the Gap from Model Weights to Production
Open-source models are advancing at a remarkable pace. New architectures like Mixture-of-Experts (MoE), Linear Attention, Native Sparse Attention (NSA), and reasoning-augmented models deliver strong performance on benchmarks — but they are significantly harder to run fast and efficiently at scale.
Getting production-grade performance from these models requires optimized inference runtimes, smart GPU scheduling, and infrastructure designed for large, complex architectures. Without this, teams often face unstable latency, inefficient resource utilization, and higher operating costs. For many developers, the gap between downloading model weights and running a reliable, scalable production system remains significant.
This partnership is designed to close that gap.
What We’re Building Together
Eigen AI and Nebius are co-developing optimized versions of frontier open-source models — including DeepSeek, GLM, GPT-OSS, Kimi, Llama, MiniMax, and Qwen — and integrating them into Token Factory. Eigen brings deep expertise in model optimization and serving systems through EigenInference, while Token Factory provides autoscaling inference infrastructure and built-in post-training tools.
The combined stack delivers:
- Optimized model implementations powered by Eigen’s advanced quantization, speculative decoding, custom CUDA and Triton kernels, KV-cache optimization, and multi-granular sparsity techniques — reducing compute and memory costs while maintaining model quality
- Autoscaling inference endpoints on Token Factory that adjust capacity automatically as traffic changes
- Dedicated model endpoints with guaranteed performance isolation and SLA enforcement
- Integrated post-training pipelines for LoRA fine-tuning, distillation, and speculative decoding draft model training
- Enterprise governance tools including team workspaces, SSO, and access controls
Developers can access these models through an API on a per-token basis, or run them as managed solutions for production workloads.
Proven Performance: #1 Output Speed Across Leading Open Models
The impact of combining Nebius’s infrastructure with Eigen AI’s optimization stack is already visible in third-party benchmarks. As tracked by Artificial Analysis, Eigen currently holds the #1 output speed across 25 of the most widely used open models, reaching up to 911 output tokens per second on GPT-OSS-120B.
Popular models such as GLM-5, GPT-OSS-120B and the Qwen3/Qwen3.5 family have consistently ranked among the fastest implementations in Artificial Analysis benchmark tracking. These optimized models are available through Nebius Token Factory, giving developers access to high-performance implementations directly through the platform.
For the full breakdown of our benchmark performance, see our companion post: Eigen AI Achieves #1 Speed Across 25 Leading Open Models on Artificial Analysis.
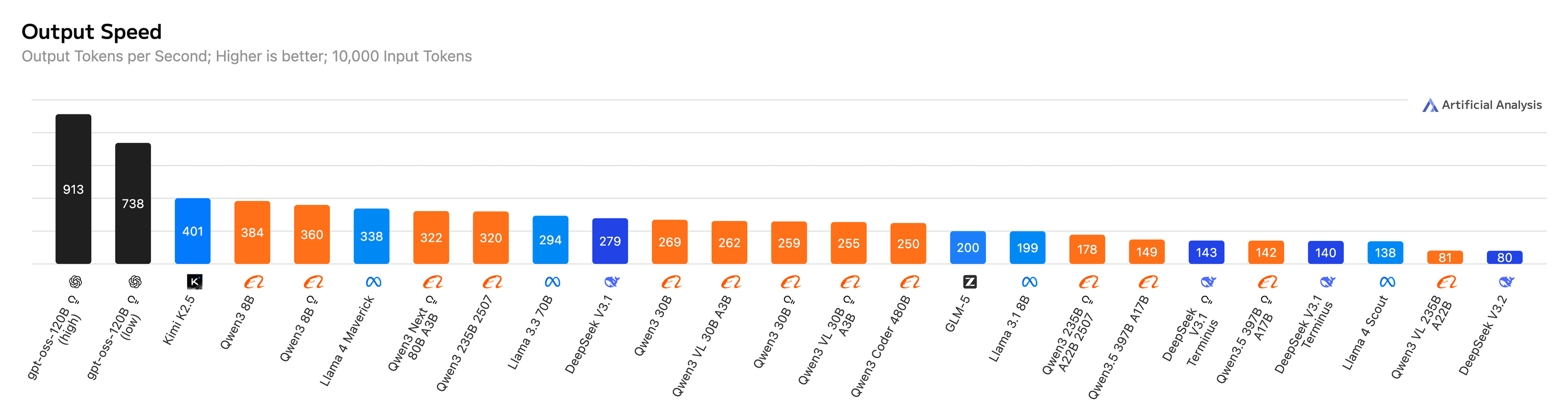
Figure 1: Eigen AI ranks as the #1 GPU-based provider for all 25 models on Artificial Analysis.
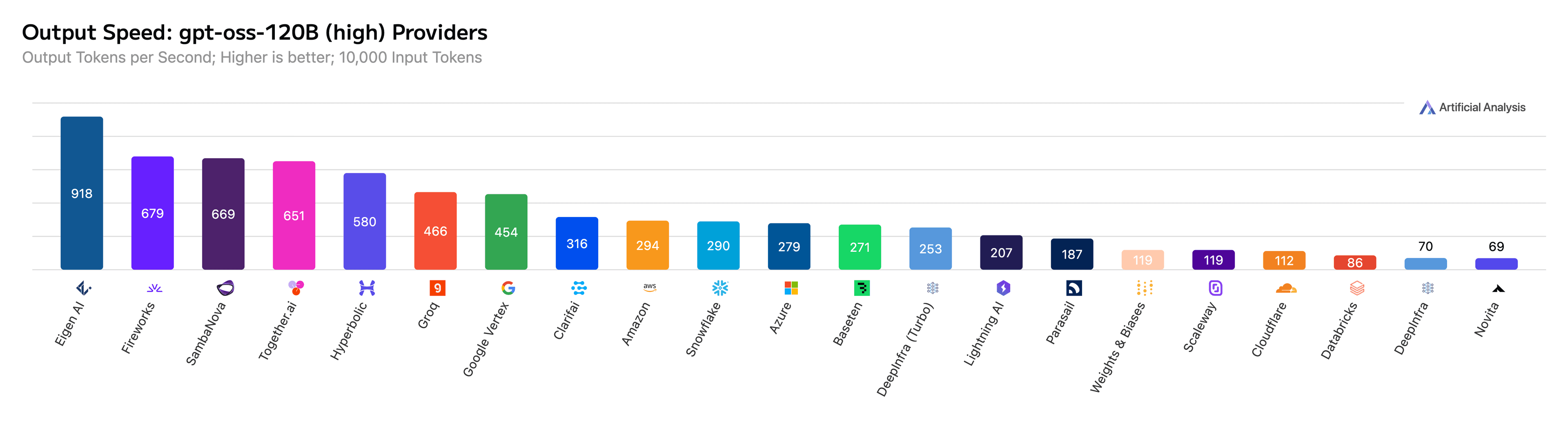
Figure 2: Eigen AI achieves 918 output tokens per second for GPT-OSS-120B on Artificial Analysis.
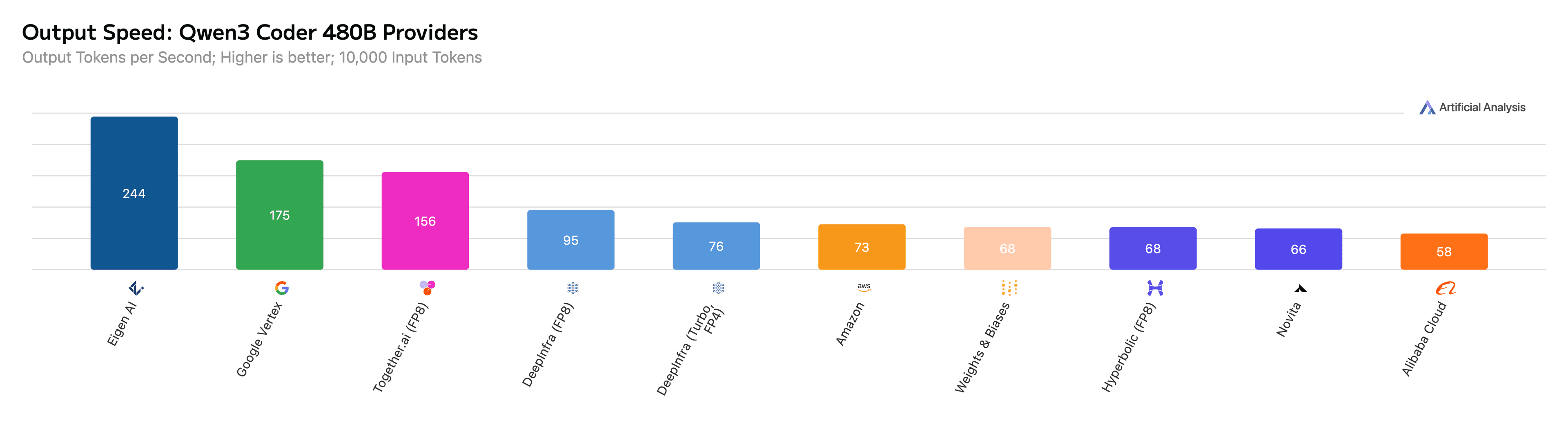
Figure 3: Eigen AI achieves 244 output tokens per second for Qwen3 Coder 480B on Artificial Analysis.
Why This Matters for Developers
For teams building on frontier open models, this collaboration shortens the path from model release to production use. Modern MoE and reasoning models require careful attention to expert routing, GPU scheduling, speculative decoding, quantization, and sparsity — optimizations that have a substantial impact on real-world performance but are complex and costly to build in-house.
Through this partnership, developers gain access to these optimizations out of the box, delivered through Token Factory’s production-ready infrastructure. The result is faster time-to-production, lower operating costs, and higher reliability — without the engineering burden of maintaining a custom inference stack.
What Our Leaders Say
Open-source models are improving incredibly quickly, but running them efficiently at scale remains challenging. By co-developing optimized versions of frontier models with Eigen AI on Token Factory, we’re making it easier for developers to access high-performance open models in production.
— Roman Chernin, co-founder and CBO of Nebius
Many frontier open models rely on Mixture-of-Experts architectures, where efficient expert routing, GPU scheduling, speculative decoding, quantization and sparsity have a big impact on performance. Working closely with Nebius allows us to bring these optimized models to Token Factory so teams can benefit from that performance without building their own inference infrastructure.
— Ryan Hanrui Wang, co-founder and CEO of Eigen AI
Get Started
Optimized open-source models co-developed by Nebius and Eigen AI are available now on Token Factory. Models can be accessed via API for self-service use, or delivered as managed solutions for production workloads.
To experience Eigen AI’s inference optimization directly, visit the Eigen AI Model Studio.
About Nebius
Nebius is an AI infrastructure company providing cloud, inference, and developer tools for teams building and deploying AI at scale. Token Factory is Nebius’s platform for running, improving, and operating open-source models in production. More info on Nebius’s official blog post and at nebius.com.
About Eigen AI
Eigen AI is a leading pioneer in Artificial Efficient Intelligence (AEI), providing high-performance solutions for enterprises demanding elite speed and accuracy. Founded by a world-class team, the company transforms raw open models into hyper-optimized, agentic intelligence. Through its integrated EigenLoop stack, Eigen AI delivers remarkably precise, hardware-efficient reliability across cloud and on-prem deployments. The company is headquartered in Palo Alto, California. More info at www.eigenai.com.
Artificial Efficient Intelligence — AGI Tomorrow, AEI Today.