
EigenData: A Self-Evolving System for LLM Function Calling Data Generation and Evaluation
EigenData: A Self-Evolving Framework for LLM Function Calling Data Generation and Evaluation
1. What Is Function Calling in LLM Agents?
Function calling enables LLM agents to interact with tools, APIs, and external environments. As LLM agents are increasingly deployed in real-world applications, the reliability of function calling systems has become a critical bottleneck. However, existing function calling datasets suffer from critical issues in environment consistency, tool reliability, and evaluation correctness.
In this post, we introduce EigenData, a self-evolving system for generating, auditing, and repairing function calling data. Applied to real-world benchmarks like BFCL, EigenData reveals that 71.5% of samples contain critical errors and provides a system-level solution to fix them.
Know more: https://arxiv.org/abs/2603.05553v1
EigenData CLI:
https://docs.eigenai.com/products/eigendata-cli/intro
.png)
2. Why Existing Function Calling Datasets Are Unreliable
Unlike standard language modeling, a function-calling data sample involves structured inputs (user queries, tool definitions, and environment state) and multi-step outputs (assistant actions, tool calls, and state transitions).
This introduces three coupled sources of complexity:
- Environment correctness
- Database schema validity
- Constraint consistency
- State transitions
- Tool reliability
- API implementation correctness
- Parameter handling
- deterministic behavior
- Trajectory validity
- Multi-turn reasoning
- Correct sequencing of tool calls
- alignment with environment state
This makes function calling datasets fundamentally harder to construct and evaluate than standard LLM training data.
2.1 Failure modes in existing datasets
Empirically, we observe that existing datasets suffer from systemic issues:
- schema mismatches between tools and ground truth
- buggy or incomplete API implementations
- logically inconsistent trajectories
- incorrect or overly rigid evaluation metrics
Notably, applied to the Berkeley Function-Calling Leaderboard (BFCL), EigenData reveals that: 71.5% of samples contain critical issues affecting correctness or evaluation.
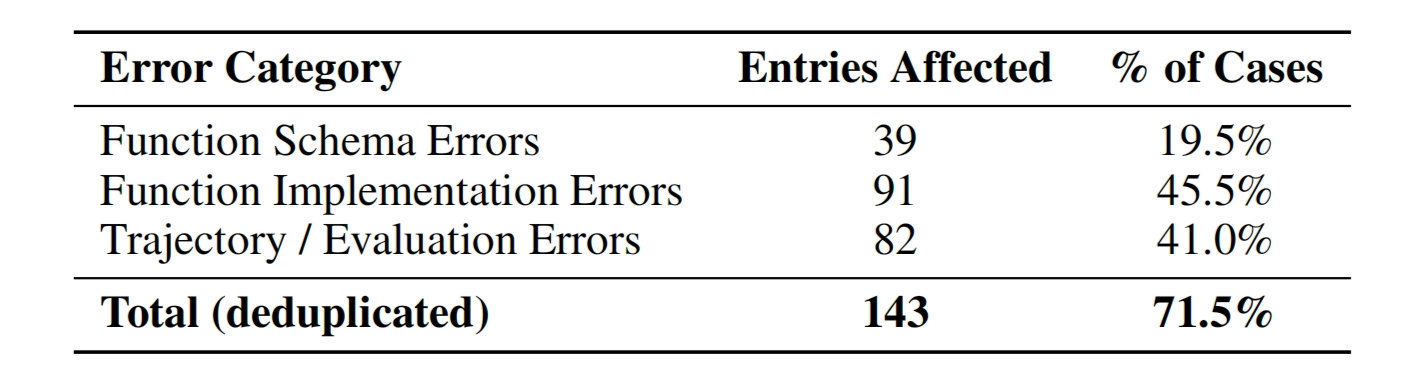
These issues can mislead model selection and obscure genuine progress.
3. EigenData: A System for Function Calling Data Generation
EigenData formulates data generation as a system-level problem, rather than a prompt engineering task.
The system consists of three interacting components coordinated by a central controller:
Each component is responsible for a distinct layer of the data generation pipeline.
3.1 DatabaseAgent: Environment Construction
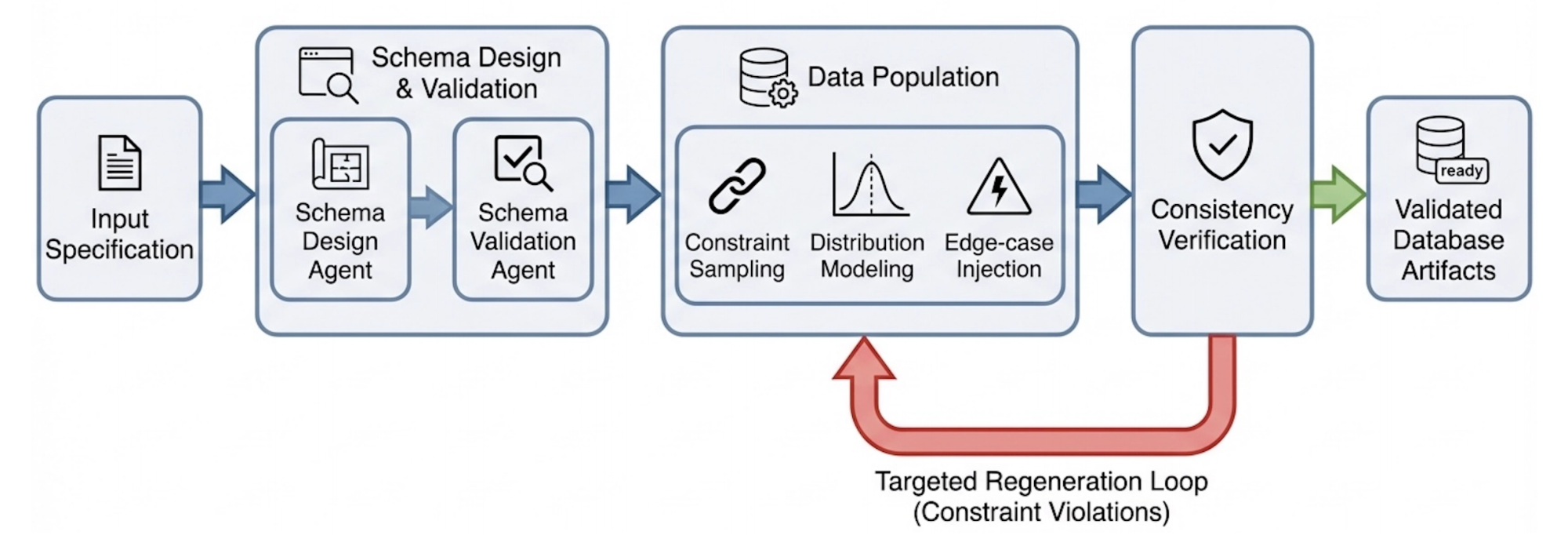
The DatabaseAgent generates structured environments that serve as ground truth.
Key responsibilities include:
- schema generation with type constraints
- population of realistic data distributions
- injection of edge cases and failure scenarios
This ensures that generated tasks are grounded in valid and diverse state spaces.
3.2 CodingAgent: Tool Synthesis and Verification
The CodingAgent generates executable tool environments, including:
- API definitions
- backend logic
- test suites
Crucially, it operates in a closed-loop debugging process:
- generate code
- execute tests
- detect failures
- iteratively repair
This guarantees that tool behavior is functionally correct and verifiable, rather than syntactically plausible.
3.3 DataAgent: Multi-Turn Trajectory Generation
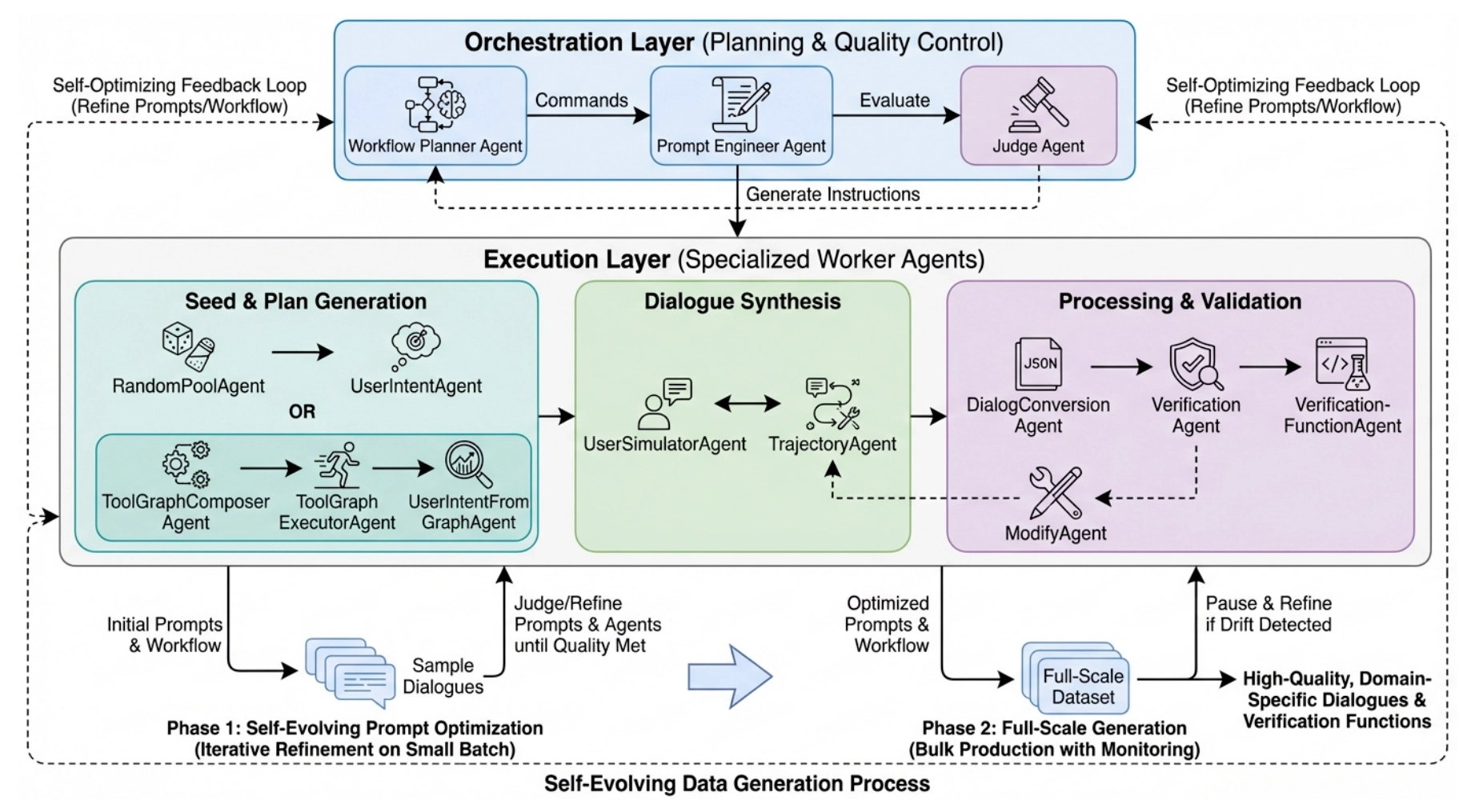
The DataAgent generates multi-turn interaction trajectories involving:
- user queries
- assistant reasoning
- tool invocations
- state updates
Beyond generation, it also evaluates and iteratively refines trajectories.
To improve data quality, EigenData employs a self-evolving strategy:
- Phase 1: prompt optimization on small batches
- Phase 2: large-scale generation with continuous monitoring
This allows the system to adaptively refine generation strategies over time.
4. Outcome-Based Evaluation for Function Calling Agents
Existing benchmarks for function-calling agents predominantly rely on action-level evaluation, including:
- exact function call matching
- strict argument matching
This formulation implicitly assumes a single canonical trajectory, which does not hold in real-world systems where multiple execution paths can yield the same valid result.
As a consequence, current evaluation protocols suffer from two systematic issues:
- false negatives: correct solutions are penalized due to trajectory mismatch
- false positives: incorrect executions pass if intermediate actions match expected patterns
EigenData instead adopts an outcome-based evaluation paradigm, where correctness is defined over the resulting environment state:
- database state consistency
- key function invocation
- correctness of critical information handling
This shift decouples correctness from specific execution traces and aligns evaluation with task-level objectives. In practice, it provides:
- invariance to alternative reasoning and execution strategies
- robustness to ordering and decomposition differences in tool usage
- improved fidelity to real-world system correctness
5. Self-Evolving Data Pipeline for Continuous Improvement
EigenData formulates data generation as a closed-loop system that integrates synthesis, validation, and repair.
The pipeline operates iteratively as:
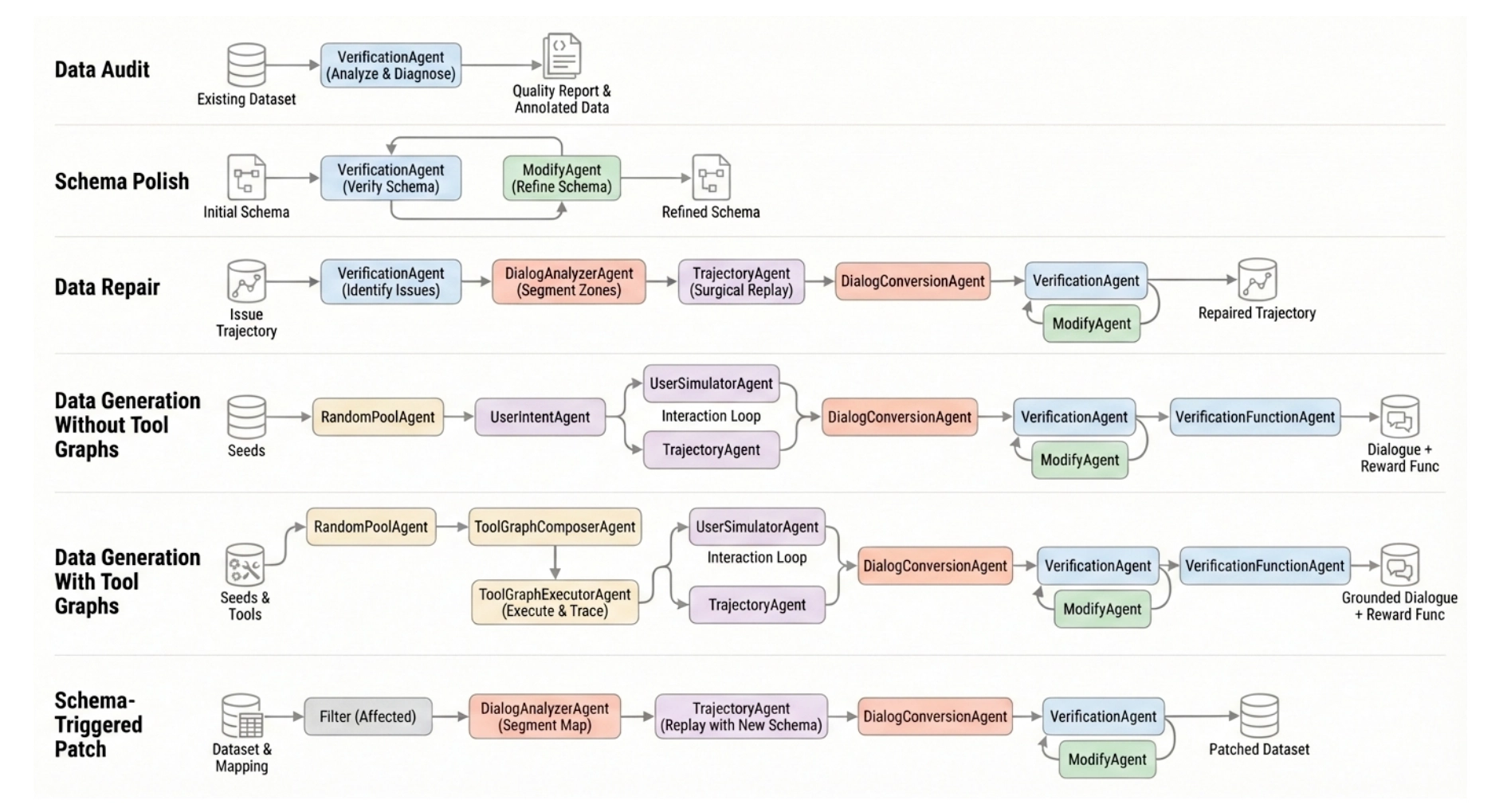
Rather than regenerating full trajectories, EigenData performs targeted, agent-driven repair through verification–modification loops, enabling localized fixes to schemas, implementations, and trajectory segments.
At each iteration, detected inconsistencies are attributed to one of three sources:
- environment construction (e.g., database state)
- tool implementation (e.g., API logic)
- trajectory generation (e.g., reasoning sequence)
Corresponding components are then updated:
- CodingAgent repairs implementation errors
- DatabaseAgent adjusts state distributions and constraints
- DataAgent refines generation strategies
This process induces a self-improving feedback loop, where system components co-evolve to reduce error rates over time.
As a result, EigenData enables:
- automatic correction of latent tool and environment bugs
- progressive alignment between trajectories and executable state
- increasing realism and consistency of generated data
Over successive iterations, the system effectively bootstraps its own data quality, reducing reliance on manual curation.
6. Case Study: Fixing the BFCL Benchmark
We instantiate EigenData on the BFCL-V3 benchmark to study its ability to audit, diagnose, and repair real-world datasets.
Rather than assuming dataset correctness, EigenData treats existing benchmarks as imperfect artifacts and performs structured analysis across multiple dimensions. Specifically, it audits:
- function schemas (type consistency, parameter constraints)
- tool implementations (correctness of execution logic)
- reference trajectories (validity of multi-turn interactions)
- user intents (ambiguity and underspecification)
This process reveals that dataset errors are not isolated, but systematically distributed across components, including:
- schema–implementation mismatches
- inconsistent ground truth or ambiguous user intents
- trajectories that violate environment constraints
- evaluation protocols that fail to capture valid solution paths
To address these issues, EigenData applies a component-wise repair pipeline, coordinated by EigenCore:
- schema errors → corrected via iterative schema refinement
- implementation bugs → resolved through test-driven debugging loops
- trajectory inconsistencies → repaired via targeted regeneration
Crucially, repairs are propagated across components to maintain cross-system consistency, ensuring that updates to schemas, implementations, and trajectories remain aligned.
After repair, the benchmark exhibits:
- improved internal consistency between tools, state, and trajectories
- more reliable evaluation signals
- qualitatively different model rankings under outcome-based metrics
7. Discussion:Why Data Quality Is the Bottleneck for LLM Agents
7.1 Data as a First-Class System
EigenData suggests a shift in how data is conceptualized in agent systems.
Rather than treating data as a static artifact, it should be viewed as a system-level object co-defined by:
- executable environments (state and constraints)
- tool implementations (behavior and interfaces)
- interaction trajectories (reasoning and control flow)
Under this view, data generation becomes a closed-loop systems problem, requiring:
- environment simulation to ground tasks in valid state spaces
- executable verification to ensure behavioral correctness
- iterative refinement to resolve inconsistencies across components
This perspective aligns data construction with the same principles used in system design: correctness, composability, and feedback-driven improvement. These improvements are not just theoretical. In practice, they translate into significantly more stable and effective post-training for interactive agents.
We demonstrate this in our work on Reliable Post-Training for Interactive Tool-Using Agents, where self-evolving data and verifiable rewards lead to large gains on real-world benchmarks.
7.2 Implications for ML Systems Design
This formulation has several implications for production ML systems.
First, data infrastructure becomes a primary scaling bottleneck, rather than a secondary concern. Improving model performance requires not only better architectures, but also tighter control over data generation and validation pipelines.
Second, evaluation must shift from trace-level supervision to outcome-level verification, ensuring that metrics reflect task success rather than intermediate behavior.
Finally, agent performance is fundamentally tied to environment fidelity. Without accurate and executable environments, improvements in model capability do not reliably translate into real-world performance.
8. Conclusion
EigenData formulates function-calling data generation as a self-evolving system that jointly models:
- environment construction
- tool synthesis
- trajectory generation
- outcome-based evaluation
By integrating these components into a unified, feedback-driven pipeline, EigenData enables:
- scalable generation of executable and verifiable data
- consistent alignment between training signals and evaluation criteria
- improved robustness of agent systems in realistic settings
This reframing positions data not as a byproduct of model development, but as a central object of system design.
Taken together, these system-level improvements extend beyond data quality itself, shaping how interactive agents can be reliably trained and evaluated in practice. In particular, they enable more stable post-training and verifiable optimization in realistic deployment settings, as we further explored in Reliable Post-Training for Interactive Tool-Using Agents.
Resource:
To make EigenData accessible to practitioners, we have released a command-line interface (CLI) that exposes the platform’s core capabilities—including data generation, schema refinement, auditing, and repair—through a unified, scriptable workflow.
The CLI and its documentation are available at: https://docs.eigenai.com/products/eigendata-cli/intro
Additional evaluation results: https://arxiv.org/abs/2603.05553v1