
Eigen AI Delivers NVFP4 Inference on Blackwell for NVIDIA Nemotron™ 3 Nano Omni at Launch
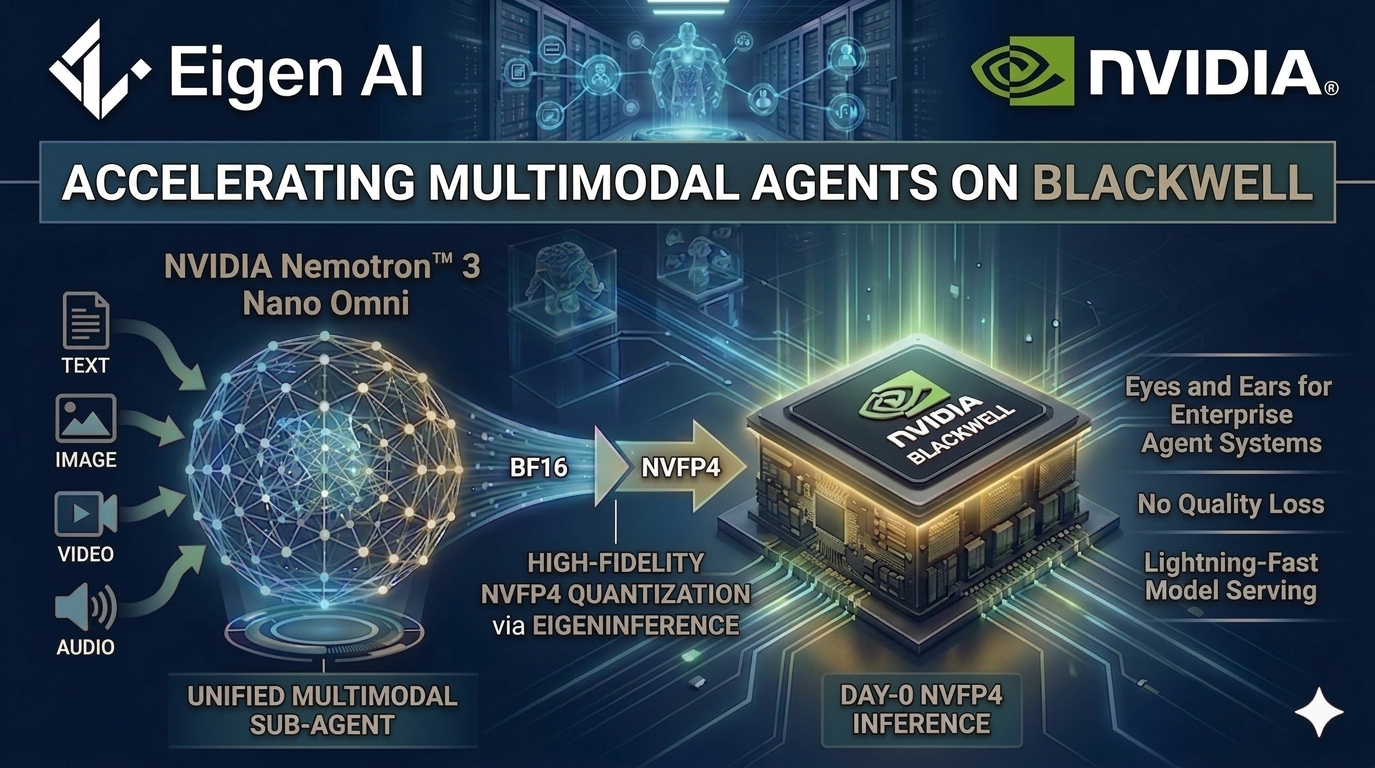
Palo Alto, California, April 28, 2026 — Eigen AI today announced available at launch inference support for NVIDIA Nemotron™ 3 Nano Omni, NVIDIA's highest-efficiency open multimodal model with leading accuracy. Through close collaboration with NVIDIA, Eigen AI has quantized Nemotron 3 Nano Omni to NVFP4 and deployed it on NVIDIA Blackwell GPUs via EigenInference, delivering 500+ output tokens per second per user with no quality loss across multiple multimodal benchmarks versus the BF16 baseline.
Nemotron 3 Nano Omni is available today at the Eigen AI Model Studio for enterprise customers and developers building next-generation multimodal agent systems.
The Challenge: Multimodal Agents Need a Perception Model That Keeps Up
Enterprise agent workflows are inherently multimodal. A single reasoning loop may need to interpret a live screen, a PDF, a video clip, and a user's voice input — often within seconds. Most production systems bolt separate models for vision, speech, and language into that loop, which introduces repeated inference passes, fragmented context across modalities, and compounding latency as agents run longer.
Enterprises need a single multimodal reasoning model that perceives and reasons across modalities in one loop, with predictable performance and full deployment control. That is the gap Nemotron 3 Nano Omni is built to fill.
Nemotron 3 Nano Omni: One Unified Multimodal Sub-Agent
Nemotron 3 Nano Omni is a 30B-A3B Mixture-of-Experts (MoE) model with a hybrid Transformer-Mamba architecture, combining NVIDIA's CRADIO vision stack and Parakeet audio stack into a single model with a 256K context window. It accepts text, image, video, and audio inputs and produces text output — functioning as the perception and context sub-agent in a larger system of agents.
Its architecture is purpose-built for continuous, always-on enterprise workloads:
- 3D convolution layers (Conv3D) for efficient temporal-spatial handling of video
- Efficient Video Sampling (EVS) for processing longer videos at reduced inference cost
- Hybrid MoE design that activates only 3B parameters per token, enabling sustained perception without the compute overhead of dense vision-language stacks
In a system of agents, Omni provides the "eyes and ears" — reading screens, interpreting documents, maintaining audio-video context — while heavier reasoning models such as Nemotron 3 Super or Nemotron 3 Ultra handle planning and execution.
Eigen AI Innovation: Production-Ready NVFP4 on Blackwell
Running a 30B-A3B multimodal model efficiently at production scale requires more than raw model performance—it demands system-level optimization across compute, memory and scheduling.
Through EigenInference, we quantize Nemotron 3 Nano Omni to NVFP4 and serve it on NVIDIA Blackwell, applying the same full-stack optimization pipeline that has made EigenInference the #1 GPU-based provider across 25 leading open models on Artificial Analysis.
With Eigeninference, Eigen AI delivers:
- NVFP4 quantization on NVIDIA Blackwell GPUs
- High-throughput multimodal inference with preserved accuracy
- Optimized expert routing and memory utilization for MoE workloads
This enables predictable and low-latency performance for continuous perception workloads such as real-time screening understanding, long-form document analysis, and streaming audio-video reasoning.
By combining NVIDIA model architecture with Eigen’s inference stack, developers can deploy multimodal agents without building custom serving infrastructure.
Why This Matters for Developers
For teams building multimodal agent systems, the path from model release to production is usually slow and complex.
Eigen at launch NVFP4 support on Blackwell accelerates this:
- Computer Use Agents — run continuous screen perception at interactive latency while execution agents handle actions
- Document Intelligence — analyze charts, tables, screenshots, and mixed-media PDFs in a single reasoning pass
- Audio & Video Understanding — maintain coherent audio-video context across long sessions for customer service, research, and monitoring workflows
Developers get the efficiency of NVIDIA's newest open multimodal architecture and the throughput of Eigen AI's Blackwell-optimized inference stack, without building or maintaining a custom serving pipeline in-house.
Get Started
NVFP4-quantized Nemotron 3 Nano Omni is available today via Eigen AI Model Studio:
- API-based access on a per-token basis for rapid prototyping
- Dedicated endpoint for production workloads
To talk with our team about deploying Omni in your agent system, get in touch with an AEI expert.
About NVIDIA Nemotron
The NVIDIA Nemotron family includes Nano, Nano Omni, Super, and Ultra models—designed to work together in enterprise agent systems. With tens of millions of downloads over the past year, Nemotron models power a growing ecosystem of open, efficient, and production-ready AI systems.
About Eigen AI
Eigen AI is a leading pioneer in Artificial Efficient Intelligence (AEI), delivering high-performance solutions for enterprises demanding elite speed and accuracy. Founded by a world-class team, the company transforms raw open models into hyper-optimized, agentic intelligence. Through its EigenLoop platform — EigenData, EigenTrain, and EigenInference — Eigen AI delivers remarkably precise, hardware-efficient reliability across cloud, private cloud, on-prem, and edge deployments. The company is headquartered in Palo Alto, California.
Artificial Efficient Intelligence — AGI Tomorrow, AEI Today.