
Beyond Larger Context Windows: Cognitive Accumulation
TL;DR
Modern LLM-based agents can reason well in short bursts, but they struggle when tasks span tens of hours with massive interaction traces and delayed feedback.
We introduce ML-Master 2.0, an autonomous agent designed for ultra-long-horizon machine learning engineering, built on a context management paradigm we call cognitive accumulation.
Instead of growing context indefinitely, ML-Master 2.0 evolves its cognition over time through a cache-inspired architecture called Hierarchical Cognitive Caching (HCC).
On OpenAI’s MLE-Bench under a fixed 24-hour budget, ML-Master 2.0 achieves a 56.4% medal rate, outperforming all reported baselines in our evaluation (including both open-source and proprietary systems).
Why ultra-long-horizon autonomy matters
Recent progress in LLMs has accelerated the development of agentic systems—AI agents that plan, act, observe feedback, and iterate.
However, real scientific discovery is inherently ultra-long-horizon, characterized by delayed feedback, high-dimensional exploration, and experimental cycles spanning days or weeks.
Machine learning engineering (MLE), for example, involves:
- Long trial-and-error cycles
- High-dimensional design choices
- Sparse and delayed rewards
- Iterative correction over extended time scales
In these settings, agents fail not because they cannot generate code, but because they lose strategic coherence over time as execution details accumulate and overwhelm the agent’s working context.
This gap motivates a core question:
How can an agent accumulate experience over long horizons without being overwhelmed by its own history?
From “more context” to cognitive accumulation
A common response to long-horizon tasks is to expand context windows or add external memory. But the paper argues that ultra-long-horizon autonomy depends on enabling context to evolve via refinement, stabilization, and reuse, rather than linearly retaining more history.
Human researchers do not remember every command, log, or failed attempt. Instead, they:
- Retain high-fidelity details only when needed
- Distill repeated experience into stable knowledge
- Abstract cross-task patterns into general wisdom
We formalize this process as cognitive accumulation: an evolutionary transformation of raw experience into increasingly stable and reusable cognitive states.
This perspective reframes context management as a dynamic system, not a static buffer.
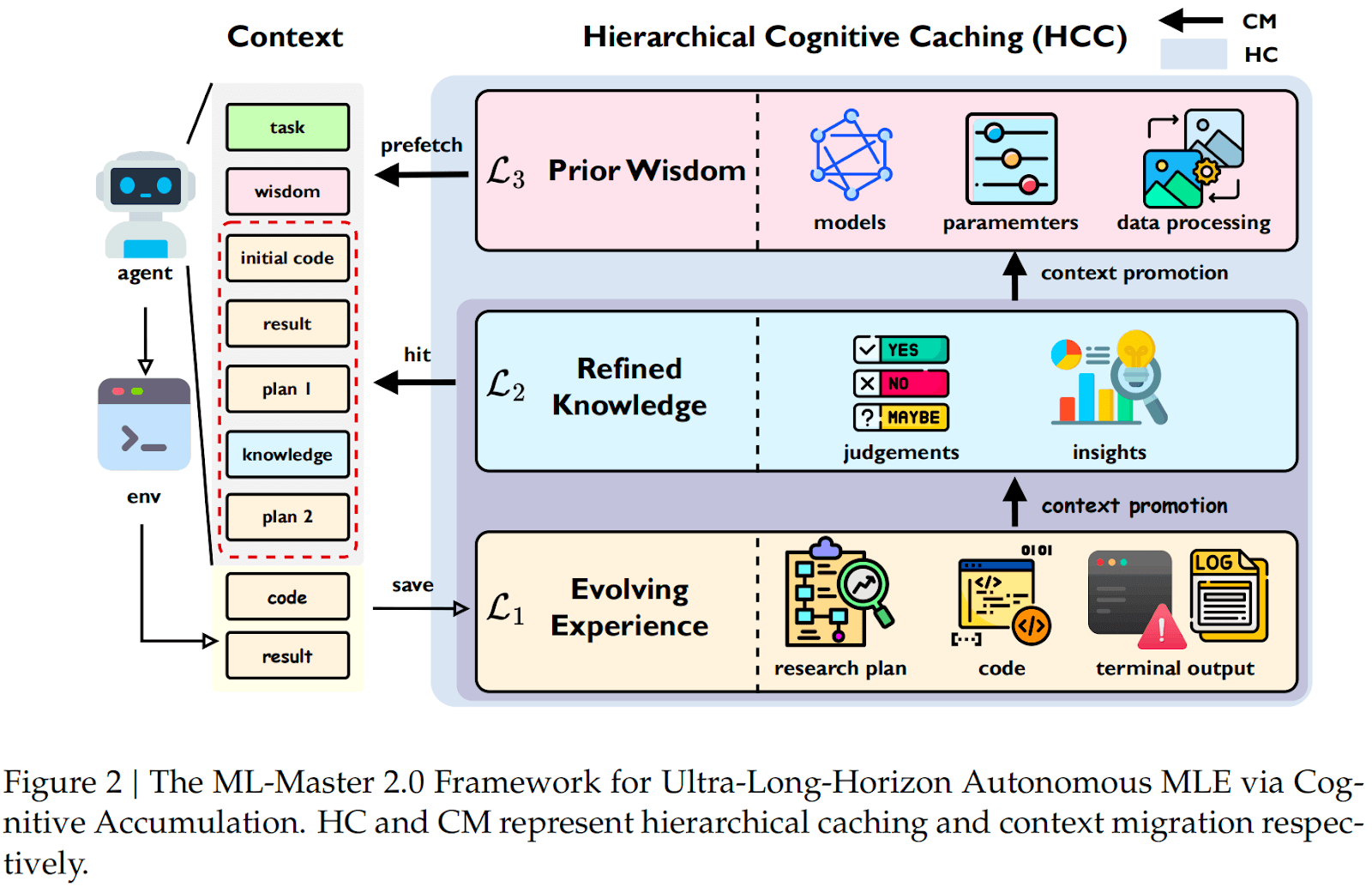
HCC: A Hierarchical Memory Architecture for Long-Horizon Agents
To operationalize cognitive accumulation, ML-Master 2.0 introduces Hierarchical Cognitive Caching (HCC), inspired by multi-level cache hierarchies in computer systems.
Instead of treating all context equally, HCC separates cognition into three layers, each serving a different temporal role.
L1: Evolving Experience: Execution Traces
- High-fidelity execution traces
- Current research plan
- Code patches, terminal outputs (e.g., error messages, metric logs)
L1 supports immediate reasoning and debugging, while limiting context growth by retaining raw traces primarily for the active execution phase.
L2: Refined Knowledge: Phase Summaries
- Phase-level summaries
- Key judgments and experimental insights
- Condensed progress summaries preserving decision rationale
After each exploration phase, raw trajectories are compressed into a refined knowledge unit, helping maintain coherence across iterative trial-and-error without carrying verbose logs.
L3: Prior Wisdom: Cross-Task Transfer
- Task-agnostic, transferable strategies
- Reusable preprocessing pipelines and model templates
- Stable hyperparameter priors
Wisdom is distilled upon task completion and stored persistently across tasks; new tasks retrieve relevant wisdom via embedding-based similarity for warm-starting.
Context migration: how cognition evolves
HCC is not just storage—it defines how information moves. ML-Master 2.0 uses three cache-like operations:
Context prefetch
Retrieve relevant prior wisdom before exploration begins.
Context hit
When constructing context, use raw events from L1 when available; otherwise fall back to compact summaries in L2.
Context promotion
Compress execution traces into refined knowledge (phase-level) and distill transferable prior wisdom (task-level).
This migration helps keep:
- Short-term execution precise
- Long-term strategy compact
- Cross-task transfer systematic
ML-Master 2.0 on MLE-Bench: 24-Hour Evaluation
ML-Master 2.0 is evaluated on OpenAI’s MLE-Bench, a benchmark comprising 75 real-world Kaggle competitions for assessing automated MLE capabilities. Each task runs under a fixed 24-hour budget in the paper’s evaluation setup.
Main results
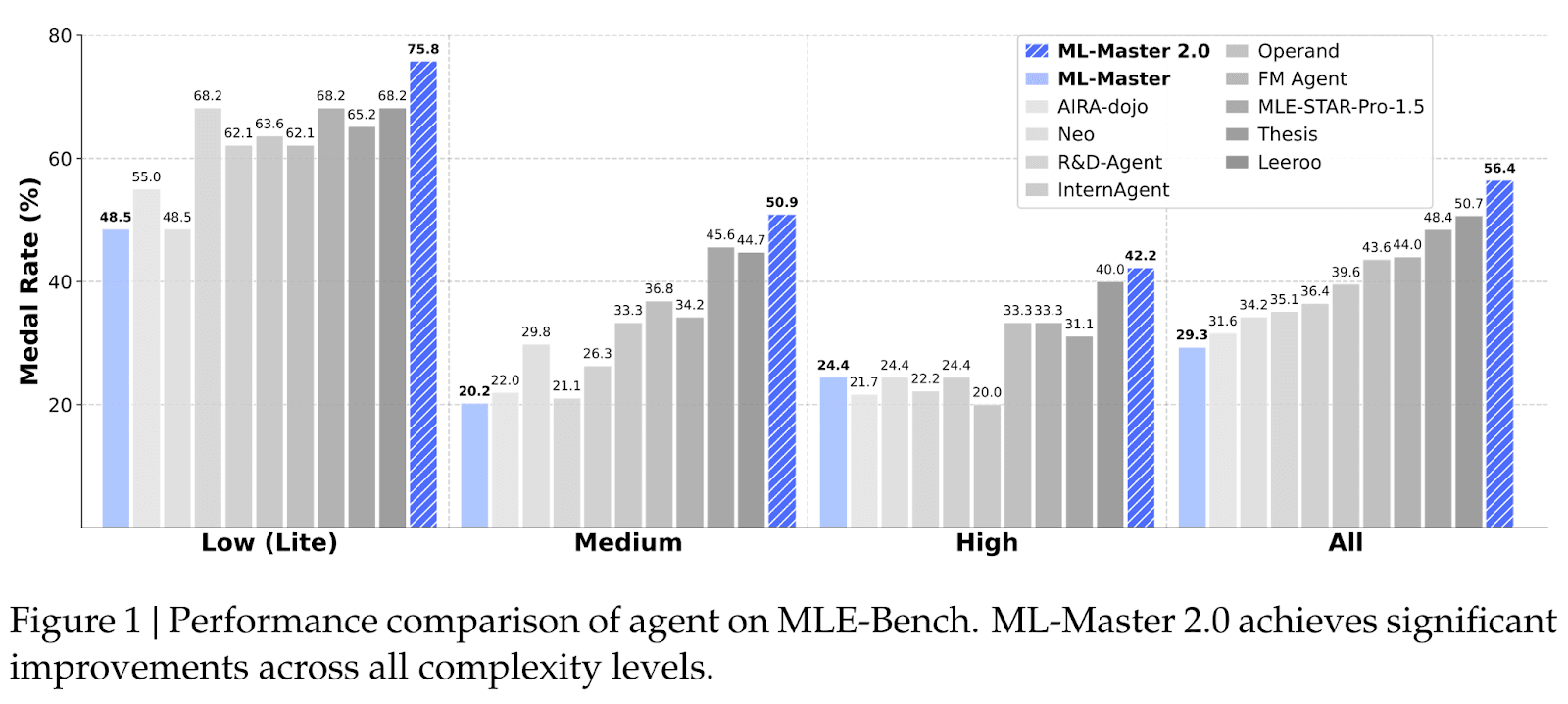
ML-Master 2.0 achieves:
- 56.4% average medal rate (Bronze / Silver / Gold)
- Strong performance across low, medium, and high complexity tasks
- A 60.7% improvement over the previous leading open-source method (35.1% → 56.4%)
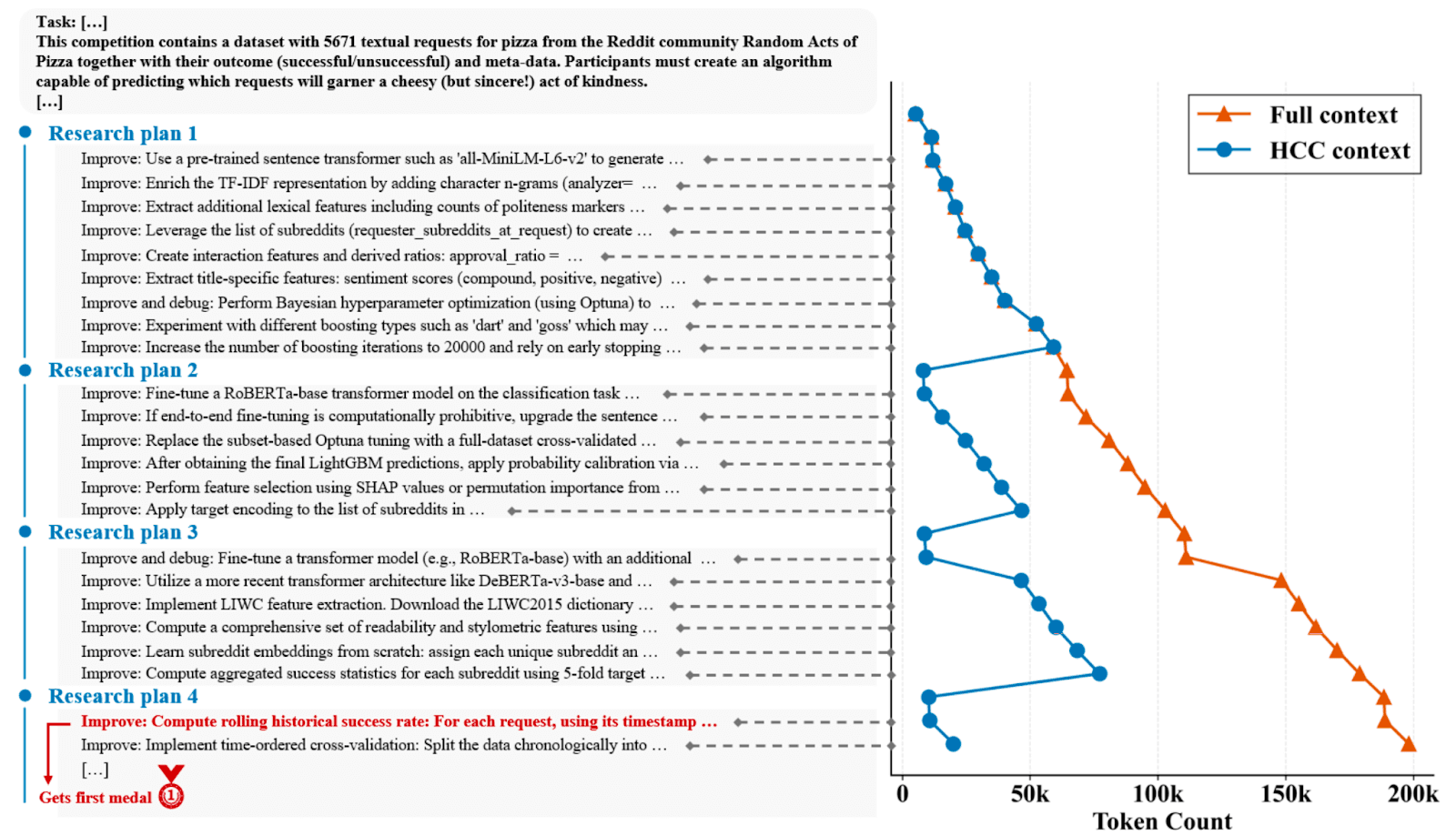
The paper also reports that performance continues improving over time during long runs, consistent with the intended accumulation behavior.
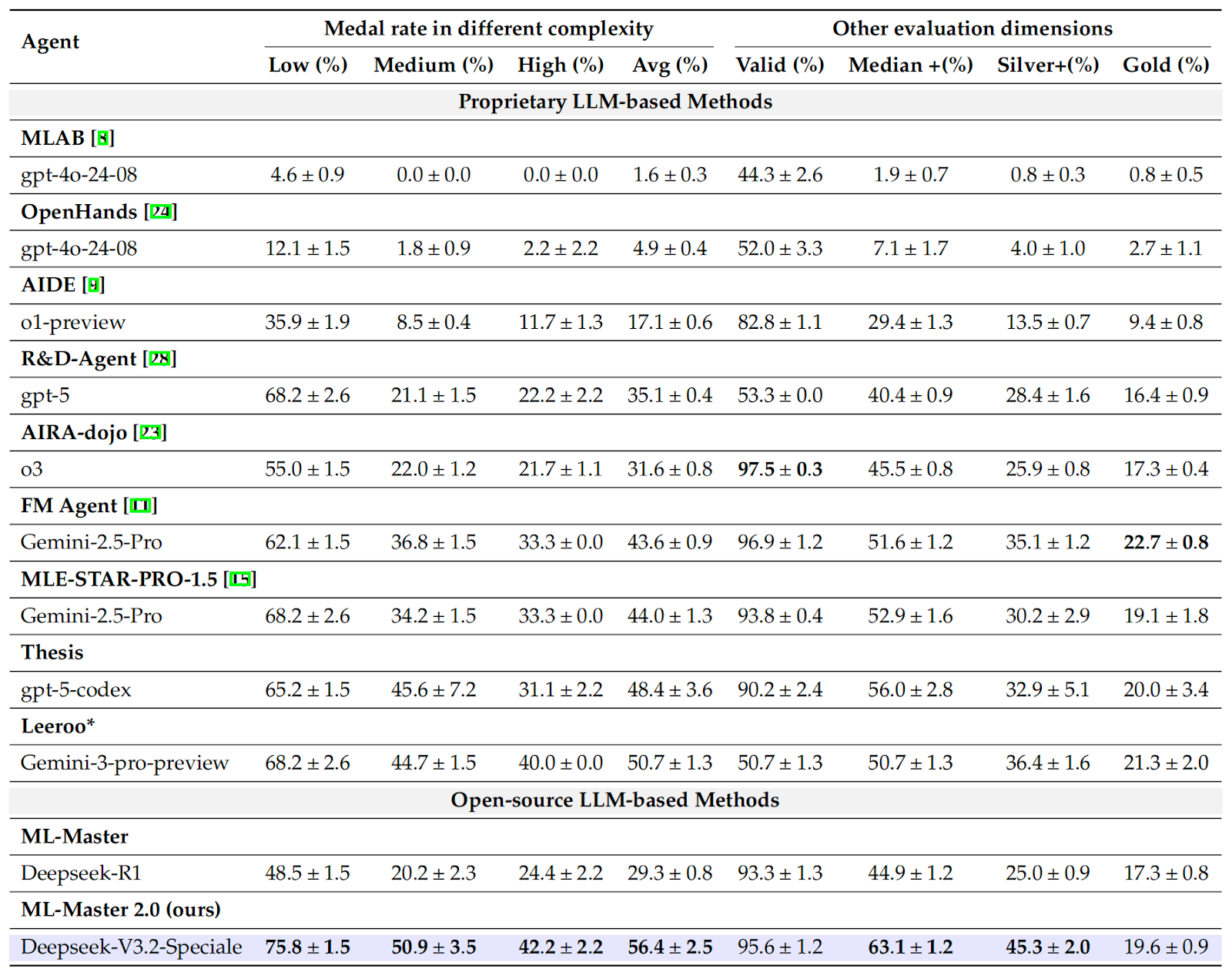
Why HCC Works: Ablation Results
The paper ablates each layer of HCC and finds:
- Removing L1 leads to a substantial degradation (e.g., valid submission rate drops to 54.5% and medal rate to 22.7% in the reported lite setting).
- Without L2, retaining raw context can still yield reasonable performance, but it hurts the ability to consistently reach medal-level solutions.
- Without L3, performance degrades due to losing strong initialization and cross-task transfer.
Overall, the full hierarchy achieves the best results, supporting the paper’s claim that structured cognitive accumulation enables long-horizon autonomy.
Implications for Agentic Science
ML-Master 2.0 suggests a broader lesson:
Long-horizon agents should not simply retain more history—they should differentiate and consolidate cognition over time.
Cognitive accumulation offers a blueprint for agents that:
- Sustain strategic coherence across extended experimental cycles
- Convert raw experience into stable, reusable knowledge
- Transfer distilled wisdom across tasks
Paper: Toward Ultra-Long-Horizon Agentic Science (arXiv: 2601.10402)