
Open-source Support DFlash Inference in SGLang and Training in SpecForge
Introduction
Eigen AI is excited to announce full open-source support for DFlash — covering both training and inference. DFlash is a breakthrough speculative decoding method that uses block diffusion to achieve up to 6.17× lossless acceleration, developed by researchers at Z Lab.
What we're releasing:
- 🚀 Inference: Full DFlash integration in SGLang (currently available in our fork, with PR pending merge), bringing production-ready serving with Radix Cache memory management, and CUDA Graph support for low-latency drafting.
- 🔧 Training: Open-source training scripts via SpecForge PR #415, enabling you to train custom DFlash draft models for any target LLM.
Traditional speculative decoding approaches like EAGLE and Medusa use autoregressive draft models that generate one token at a time, limiting parallelism. DFlash introduces a fundamentally different paradigm: block diffusion — generating an entire block of draft tokens in a single forward pass through parallel denoising. This enables massive speedups while maintaining lossless generation quality.
Code and resources:
| Resource | Link |
|---|---|
| SGLang Inference | eigen-ai-labs/sglang-public (branch: release-dflash) |
| Training Scripts | SpecForge PR #415: dLLM Online Training |
Understanding the DFlash Approach
The core innovation of DFlash (developed by Z Lab) addresses the main bottleneck in speculative decoding: the trade-off between draft model size and acceptance rate. While diffusion models offer parallel generation, they are typically too computationally expensive to serve as effective speculators.
The Architectural Breakthrough: Feature-Conditioned Drafting
DFlash solves this by fundamentally changing the role of the draft model. Rather than being a standalone “reasoner,” the draft model acts as a parallel decoder for the target model's hidden states.
The method relies on the observation that a large model's hidden representations implicitly contain information about future tokens. By conditioning a lightweight diffusion model on these rich semantic features, DFlash enables high-quality block generation (as shown in Figure 2) without the latency of a large autoregressive drafter.
This approach effectively decouples reasoning (handled by the target model's prefill/verify steps) from generation (handled by the parallel diffusion drafter), allowing for:
- Massive Parallelism: Generating 16+ tokens in a single forward pass.
- Minimal Overhead: Using a tiny 5-layer model that shares embeddings with the target.
- High Acceptance: Leveraging the target's own internal state to guide the draft.
Architecture Overview
The DFlash architecture integrates a parallel diffusion drafter into standard autoregressive pipelines. Eigen AI has contributed DFlash inference support to SGLang (currently available in this fork, with PR pending merge), bringing production-ready serving with Radix Cache memory management, and CUDA Graph support for low-latency drafting. It works in three main stages: feature extraction from the target model, parallel drafting with a specialized lightweight model, and fused verification.
1. DFlash Draft Model (Qwen3ForCausalLMDFlash)
The draft model essentially functions as a conditional denoiser. Instead of predicting tokens one by one (autoregressive), it predicts an entire block of tokens at once based on:
- Semantic Context: What the target model “thinks” about the current state.
- Random Noise: A starting point for the diffusion process.
Mechanism:
Input Fusion: The model takes two inputs:
noise_embedding: A learnable embedding initialized with Gaussian noise, representing the “slots” to be filled.target_hidden: High-level features extracted from the target model.
Dual-Input Attention:
- Queries: Generated only from the
noise_embedding. - Keys and Values: Generated by separately projecting
target_hiddenandnoise_embedding, then concatenating the results along the sequence dimension.
Non-Causal Processing: The attention mask is full (all-to-all). This bidirectional visibility allows the model to enforce consistency across the entire generated block in a single forward pass.
2. Multi-Layer Feature Extraction
To give the draft model “reasoning” capabilities without the cost, we extract hidden states from specific layers during the prefill or verification phase.
Data Flow:
- Extract: Pull hidden state tensors from the specified layer indices.
- Concatenate: Join these tensors along the feature dimension.
- Project: Pass the concatenated tensor through a linear projection layer and RMSNorm to match the draft model's hidden dimension.
This projected tensor becomes the target_hidden input for the draft model, effectively “seeding” it with deep semantic information.
3. Fused Verification Kernel
Once the draft block is generated, it must be verified against the target model. The system uses a fused CUDA kernel that performs the following in a single GPU operation:
- Logit Comparison: Compares the target model's logits for the draft block against the draft tokens.
- Prefix Matching: Finds the longest prefix where the draft tokens match the target's greedy predictions (or sample).
- State Updates: Automatically updates the request's status and KV cache pointers based on the accepted length.
This fusion eliminates the overhead of launching multiple kernels and copying data back and forth to the CPU.
Experimental Results
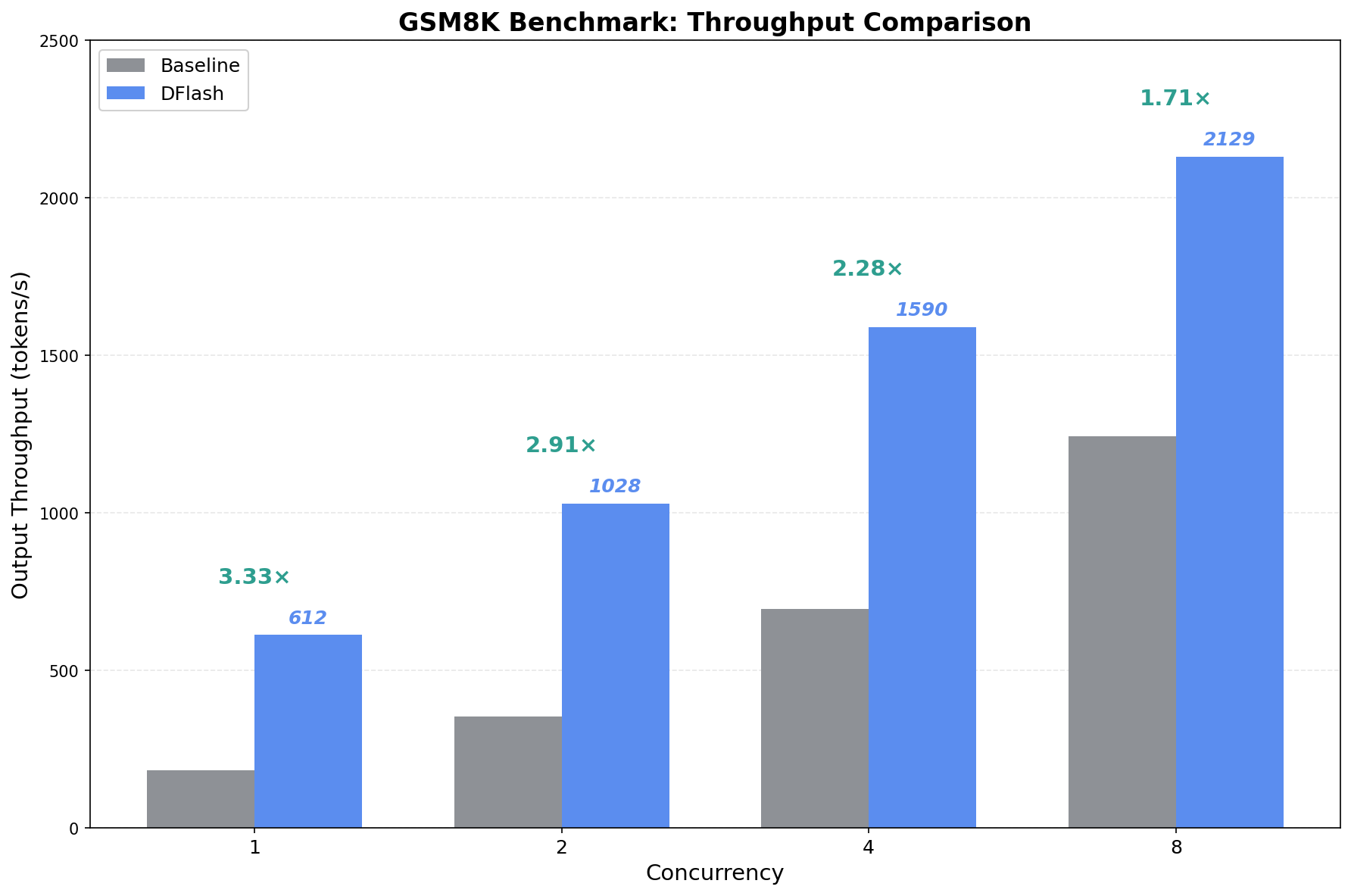
Figure 1: Comprehensive GSM8K benchmark results on a single NVIDIA H200 GPU.
Performance Benchmarks (NVIDIA H200)
| Concurrency | Throughput (DFlash) | Throughput (Baseline) | Latency (DFlash) | Latency (Baseline) |
|---|---|---|---|---|
| 1 | 612 tok/s | 184 tok/s | 64.2s | 215.3s |
| 2 | 1,028 tok/s | 353 tok/s | 38.7s | 112.4s |
| 4 | 1,590 tok/s | 696 tok/s | 24.9s | 57.1s |
| 8 | 2,129 tok/s | 1,243 tok/s | 14.8s | 35.2s |
Roadmap & Next Steps
This release marks the initial milestone in our DFlash integration roadmap. Eigen AI’s engineering team is currently focused on two critical optimizations to further push the boundaries of low-latency serving:
- Computation Overlap: Implementing advanced scheduling to overlap the draft model's execution with the target model's verification phase, aiming to hide the drafting latency entirely.
- Kernel Fusion: Developing fused kernels to minimize kernel launch overhead, specifically targeting high-concurrency throughput.
Usage
Starting the Server
python -m sglang.launch_server \
--model-path Qwen/Qwen3-4B \
--speculative-algorithm DFLASH \
--speculative-draft-model-path z-lab/Qwen3-4B-DFlash-b16 \
--speculative-dflash-block-size 16 \
--port 30000Open-Source Training: Train Your Own DFlash Model
Another key part of Eigen AI’s open-source release is the training pipeline. We've contributed DFlash training support to SpecForge via PR #415: dLLM (DFlash) Online Training. This enables you to train custom DFlash draft models for any target LLM.
How It Works

Figure 2: The DFlash Training Pipeline. The draft model is trained to predict the next block of tokens by conditioning on features extracted from the frozen target model's hidden states.
The draft model learns to predict masked tokens conditioned on the target model's hidden states. Given input like [token, MASK, MASK, ..., MASK], it recovers the original sequence — but critically, it does so using rich context extracted from the target model's internal representations.
This is why a 5-layer draft model works: it doesn't need to “understand” the input independently, just learn the mapping from target hidden states to tokens.
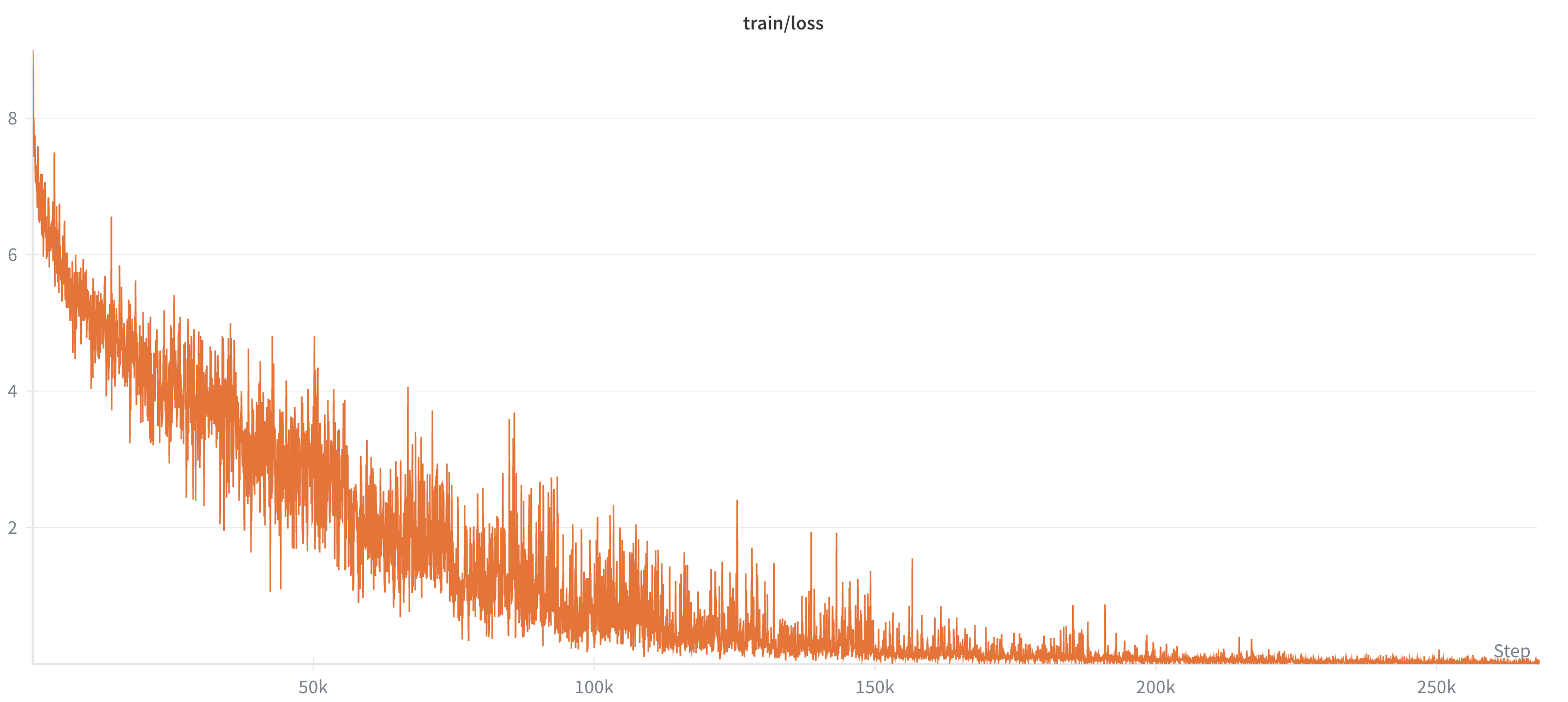
Figure 3: Training loss convergence.
Final Words
Eigen AI is dedicated to build high‑performance AI for enterprises—customize, compress, and deploy advanced models with enterprise-grade speed, accuracy, and unit economics—today.
Acknowledgments
DFlash was developed by Jian Chen and Zhijian Liu at Z Lab.
References:
- DFlash: Block Diffusion for Flash Speculative Decoding — Original project page with full benchmarks
- SGLang: High-performance Serving Framework for Large Language Models and Multimodal Models
- SpecForge: Train Speculative Decoding Models Effortlessly and Port Them Smoothly to SGLang Serving
- EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty