
Teaching Tool-Use Agents from Their Own Mistakes
TL;DR
- The question. After supervised fine-tuning, tool-use agents still fail in stubbornly specific ways — wrong item picked, wrong order updated, missing confirmation. Where should the next round of training data come from?
- The trick. Let the model tell us. We cluster the agent's own validation failures into recurring error patterns, then synthesize targeted RL tasks that stress exactly those weak spots.
- The headline. On Tau2-Bench Retail with Qwen3-30B-A3B-Thinking, error-driven RL lifts Pass^1 from 54.2 → 75.9 (SFT) → 82.5 (SFT + targeted RL), and Pass^4 — the strict consistency metric — from 34.2 → 52.6 → 61.4.
- In context. That 82.5 places a 3B-active model between Qwen3.5-397B-A17B and GPT-5.2 on the public τ-bench Retail leaderboard, ahead of Claude Opus 4.5 and Gemini 3 Pro (we use Claude 4.5 as the user simulator).
A failure most agents make
Here is a sketch of a real failure mode we saw repeatedly after SFT. The user has two open orders, both containing similar items:
User: "Can you cancel the blue mug from my recent order?"
Agent: (calls
cancel_itemon Order #A — the wrong order, which also contains a blue mug)Agent: "Done — your blue mug has been cancelled."
The agent understood the high-level intent. It knew the right tool. It generated a syntactically valid call. And it still failed, because resolving "my recent order" requires asking the user, or at minimum disambiguating between two candidate records.
This kind of failure — confident, plausible, and wrong — is exactly the kind that imitation learning struggles to fix. The SFT data covers the easy path; the model only encounters two-order ambiguity in its own rollouts, where there's no teacher to correct it.
That observation is the seed of this work.
Why SFT alone hits a ceiling
The standard recipe for tool-use agents is supervised fine-tuning on synthetic interaction trajectories — successful rollouts of an agent, a user simulator, and an executable environment. It works. It's how you get a model that knows tool schemas, generates valid arguments, and tracks state across turns.
But SFT is fundamentally off-policy: the model imitates trajectories produced by some other policy, not the states it actually visits when it's the one driving. In multi-turn tool use, small mistakes compound into states that supervised data barely covers. SFT builds broad competence, then leaves the model alone exactly where it most needs help.
Reinforcement learning on the executable environment is the natural next step — the agent rolls out, the environment scores the final state, and rewards flow back. The catch: RL is only as good as its task distribution. If the training tasks don't target the model's actual weaknesses, RL just rehearses what SFT already taught, or worse, it finds reward-hacking shortcuts.
So the real question after SFT isn't more RL — it's which tasks.
The loop: train on what the model is currently bad at
Our answer is a loop with one stable anchor and one growing artifact:
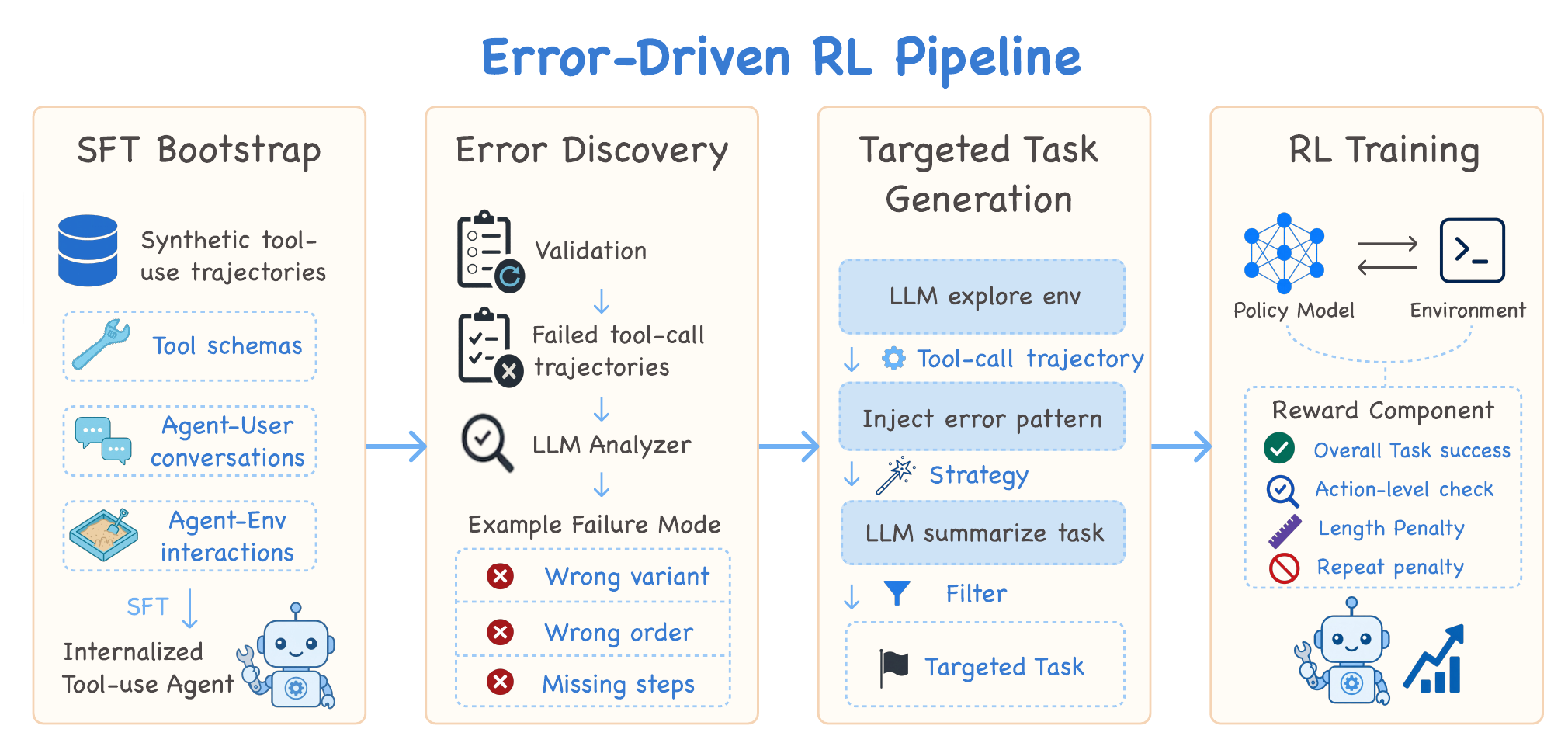
The four stages are: (1) SFT Bootstrap on synthetic tool-use trajectories to internalize the basic mechanics of tool use; (2) Error Discovery, where an LLM analyzer reads failed trajectories from validation and clusters them into recurring failure modes — wrong variant, wrong order, missing steps, and so on; (3) Targeted Task Generation, where an LLM explores the environment, injects a chosen error pattern into a feasible trajectory, and filters the resulting tasks for executability; and (4) RL Training with a composite reward (task success + action-level checks + length penalty + repeat-call penalty). The loop closes when we re-analyze the new model's failures and feed another batch of targeted tasks back into the pool.
The key implementation detail: in our current setup, every RL round restarts from the same SFT checkpoint and trains on the union of all targeted tasks accumulated so far. We don't continue training from the previous RL model, and we don't throw away earlier rounds' tasks. What grows between rounds is the task pool; the policy we're training always launches from the same well-conditioned starting point.
We chose this for training stability, but it isn't the only sensible option — continuing from the previous RL checkpoint, or weighting recent tasks more heavily, are alternatives we think are worth exploring. The point of the loop is the closed feedback, not the specific re-initialization rule.
Each pass of the loop reshapes the task distribution toward whatever the most recent model was bad at. Early rounds tend to surface basic argument-grounding errors; later rounds shift toward clarification, confirmation, and other long-horizon control issues that only show up once the easy stuff is fixed.
The rest of this post walks through each box.
Inside the loop
1. Bootstrap with SFT
We start by fine-tuning on synthetic Tau-bench-style trajectories generated by Trajectory2Task. Each trajectory is a full multi-turn record — observations, tool calls, environment feedback, and reasoning — so the model learns the mechanics: which tool to pick, how to follow schemas, how to keep state across turns.
Nothing exotic here. This stage exists to give RL a stable, reasonably competent starting policy. The interesting work begins after the model has saturated what imitation can teach it.
2. Mining failure patterns
We run the SFT model against validation tasks and look at the failures. For each losing trajectory, we hand an LLM judge the user request, dialogue history, tool calls, and tool outputs, and ask it for one thing: what went wrong? We then cluster the explanations into recurring patterns.
Three families dominate the post-SFT failure landscape on Retail:
| Pattern | What it looks like |
|---|---|
| Item & argument selection | Right intent, wrong specifics: picks the wrong product variant, mixes item IDs across orders, or hands the tool an invalid argument value. |
| Multi-order reasoning | The user has multiple active or historical orders; the model updates the wrong one or attributes an item to the wrong record. |
| Execution control | Recognizes that confirmation is needed but never confirms. Terminates before all required steps. Calls the same tool repeatedly without making progress. |
These aren't "the model needs more data." They're "the model needs to be challenged on precise grounding, multi-record reasoning, and long-horizon execution." That's a much more actionable diagnosis.
3. Synthesizing targeted tasks
Now the loop closes. For each error pattern, we generate new RL tasks that deliberately provoke it — while preserving a feasible solution path so the reward signal is well-defined.
Concretely, we use a strong LLM agent to explore the executable environment first and produce successful trajectories grounded in real tool calls and feasible state transitions. A second LLM then converts each trajectory into a natural-language user task, with one twist: it injects a chosen difficulty pattern into the wording.
A worked example:
Source trajectory: User has Orders #A (blue mug, ceramic vase) and #B (blue mug, frying pan). Agent successfully cancels the blue mug from Order #A.
Naïve generated task: "Cancel the blue mug from Order #A."
Targeted generated task (multi-order ambiguity injected): "Hey, can you cancel the blue mug from my recent order? I think it was the one with the vase too."
The feasible solution still exists, but the agent now has to either resolve the order from the side hint, or — better — ask a clarifying question before acting. We run the same recipe for confirmation-required actions, ambiguous product variants, and so on.
This is the part of the framework we're most excited about: the difficulty isn't bolted on by hand-written rules; it's shaped by what the model actually got wrong last round.
4. RL with anti-hacking rewards
We train with GRPO against the executable environment. Task-success reward is the backbone, but pure outcome rewards on tool-use environments are easy to game, so we add three guardrails:
- A repeated-call penalty to discourage tool-call loops and cosmetic "progress."
- Action-level reward checks that verify intermediate tool calls are valid and aligned with the task — not just the final state.
- A token-length penalty to keep reasoning traces from ballooning.
Together these keep the policy honest: it has to actually solve the task, with valid intermediate steps, in a reasonable budget.
Results: from 54% to 82%
We evaluate on the Tau2-Bench Retail domain — an executable customer-support environment with order cancellation, modification, returns, exchanges, and preference-sensitive selection. The base model is Qwen3-30B-A3B-Thinking-2507. RL training tasks are generated from databases that share Retail's tool schemas and rules but whose users, orders, and products are disjoint from the test environment.
We report Pass^k: the probability that all k repeated trials succeed. Pass^1 is the headline; Pass^4 measures how reliably the agent solves the same task on multiple tries.
| Model | Pass^1 | Pass^2 | Pass^3 | Pass^4 |
|---|---|---|---|---|
| Base | 54.2 | 44.7 | 39.5 | 34.2 |
| SFT | 75.9 | 64.5 | 57.5 | 52.6 |
| SFT + error-driven RL | 82.5 | 73.0 | 66.2 | 61.4 |
Two things stand out:
SFT does most of the work — but not the hardest work. It alone closes about three-quarters of the gap between Base and the final model on Pass^1. That's the broad-competence story: tool selection, schema following, basic state tracking.
Error-driven RL widens the gap most where it counts. The Pass^1 lift from RL is +6.6, but the Pass^4 lift is +8.8 — RL helps more on the strict consistency metric than on the lenient one. That's exactly what you'd expect if RL is working on the long tail of failure modes rather than the average case. Reliable agents have to handle the rare states; that's where the lift shows up.
How does this compare to the public leaderboard?
The interesting comparison isn't just against the SFT baseline — it's against the τ-bench public leaderboard, where frontier models from every major lab compete on the same Retail tasks under the same evaluation protocol.
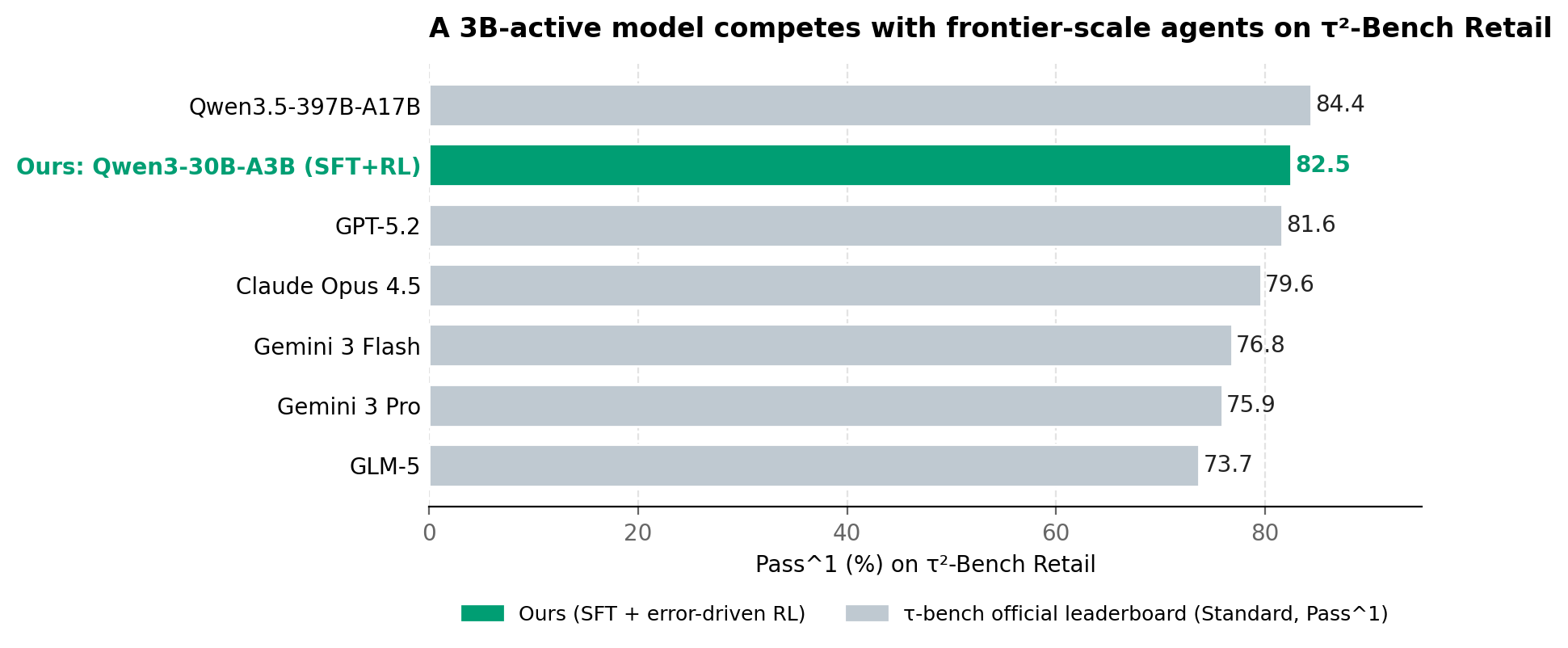
Our model lands at 82.5 Pass^1, slotting in between Qwen3.5-397B-A17B (84.4) and GPT-5.2 (81.6), and ahead of Claude Opus 4.5, Gemini 3 Pro/Flash, and GLM-5 (we use Claude 4.5 as the user simulator on the same τ-bench Standard Retail tasks).
The size context makes the result sharper. Our base model — Qwen3-30B-A3B-Thinking — has roughly 3 billion active parameters. The leaderboard leader has 17B active out of a 397B mixture-of-experts; the closed frontier models are widely believed to be much larger still. We're not claiming "small model beats big model" in any absolute sense — Qwen3-30B-A3B is already a strong tool-use base, and the leaderboard models are zero-shot evaluations of general-purpose systems. But we are saying something more specific and, we think, more useful: on a well-defined tool-use domain, a few hundred targeted RL tasks generated from the model's own failures can close the gap that scale alone would otherwise pay for.
The reward shape matters at least as much as the task pool
We ablated the reward design to see how much each piece contributes. Same model, same task pool, only the reward changes:
| Reward | Pass^1 | Pass^2 | Pass^3 | Pass^4 |
|---|---|---|---|---|
| Full reward (ours) | 82.5 | 73.0 | 66.2 | 61.4 |
| − repeated-tool-call penalty | 79.2 | 66.4 | 57.2 | 50.0 |
| Task-success only (sparse) | 66.7 | — | — | — |
Two things to notice.
The repeated-tool-call penalty is mostly a consistency knob. Removing it costs 3.3 points on Pass^1 but 11.4 points on Pass^4. The penalty's job is to discourage the model from spamming the same tool call when it's stuck — and that kind of degenerate loop hurts the consistency of the agent more than its average behavior, because every now-and-then a stuck rollout tanks the whole "all k trials succeed" criterion.
Sparse outcome rewards collapse. When we strip everything down to "did the task succeed," Pass^1 drops to 66.7 — worse than SFT alone. We watched what happened: the model exploited the environment in exactly the ways the auxiliary rewards were designed to prevent. It looped on the same tool call, padded reasoning traces, and stopped following its own plans. The task-success signal was technically pointing in the right direction, but it wasn't dense enough to stop the policy from finding shortcuts that satisfy the letter of the reward and not its spirit.
The high-level lesson: on executable tool-use environments, the task pool tells the model what to learn; the auxiliary rewards tell it what not to do. You need both.
What this means for tool-use agents
The traditional advice is "scale up your synthetic data." This work suggests a complementary lever: let the model's failure distribution shape your training distribution. SFT builds breadth; error-driven RL closes specific gaps. They're not substitutes — they're stages.
A few takeaways we'd put on a poster:
- Failure analysis is curriculum design. The cluster names that fall out of an LLM judge ("multi-order reasoning," "missing confirmation") aren't post-hoc commentary — they're prompts for the next data generation pass.
- Generic RL tasks underperform targeted ones once SFT has saturated the easy stuff. The marginal task should look like a marginal failure.
- One stable starting point makes the loop tractable. In our setup we restart each RL round from the SFT checkpoint and train on the accumulated task pool. It's not the only valid choice, but it makes runs reproducible and isolates "the new tasks helped" from "the model just got more gradient steps."
- Outcome rewards alone aren't enough — and the gap is large. Stripping the reward down to pure task success drops Pass^1 from 82.5 to 66.7, below the SFT baseline. On executable tool-use benchmarks, action-level checks and anti-hacking penalties aren't a polish step; they're load-bearing.
Limitations and what's next
We've shown the recipe on one domain (Retail) and one base model (Qwen3-30B-A3B-Thinking). The error taxonomy that fell out — item selection, multi-order reasoning, execution control — is Retail-flavored, even though we suspect the types of pattern (precise grounding, multi-record reasoning, long-horizon execution) generalize. The obvious next steps:
- Run the loop on Airline and Telecom domains to see whether the error taxonomy is domain-shaped or capability-shaped.
- Iterate the loop more than once and watch how the error distribution shifts after each round — if it stops shifting, you've hit a real ceiling rather than a curriculum gap.
- Push the same recipe on smaller base models, where post-SFT failures are likely concentrated in different patterns and the loop should be most informative.
If you're training tool-use agents and your post-SFT model still fails on things you "thought were obvious," try clustering its failures before generating more data. The model already knows what it's bad at — you just have to ask it.