
VISTA: Scaling Agentic Reinforcement Learning for Tool-Integrated Visual Reasoning
While recent Vision-Language Models (VLMs) have demonstrated impressive capabilities in describing images, they often struggle when asked to “think” with them—especially when solving multi-step problems that require external tools like calculators or object detectors.
Today, we are introducing VISTA-Gym, a scalable training environment designed to incentivize tool-integrated reasoning, and VISTA-R1, a model trained within this environment that significantly outperforms state-of-the-art baselines.
VISTA-R1-8B outperforms comparable open-source models by 9.51%–18.72% across 11 reasoning-intensive benchmarks, demonstrating that reinforcement learning (RL) is key to unlocking true agentic capabilities in VLMs.
The Challenge: Why Naively Adding Tools Fails
Current approaches to equipping VLMs with tools often rely on simple prompting or supervised fine-tuning. However, our research shows a counter-intuitive result: directly augmenting VLMs with tools often degrades accuracy.
Without explicit training on when and how to use tools, models treat them as distractors. They struggle with:
- Invocation schema: getting the JSON format wrong.
- Reasoning logic: failing to integrate the tool’s output back into the answer.
- Coordination: not knowing whether to calculate first or look at the image first.
We identified that to solve this, models need to transition from passive perception to active, tool-integrated reasoning (TIR).
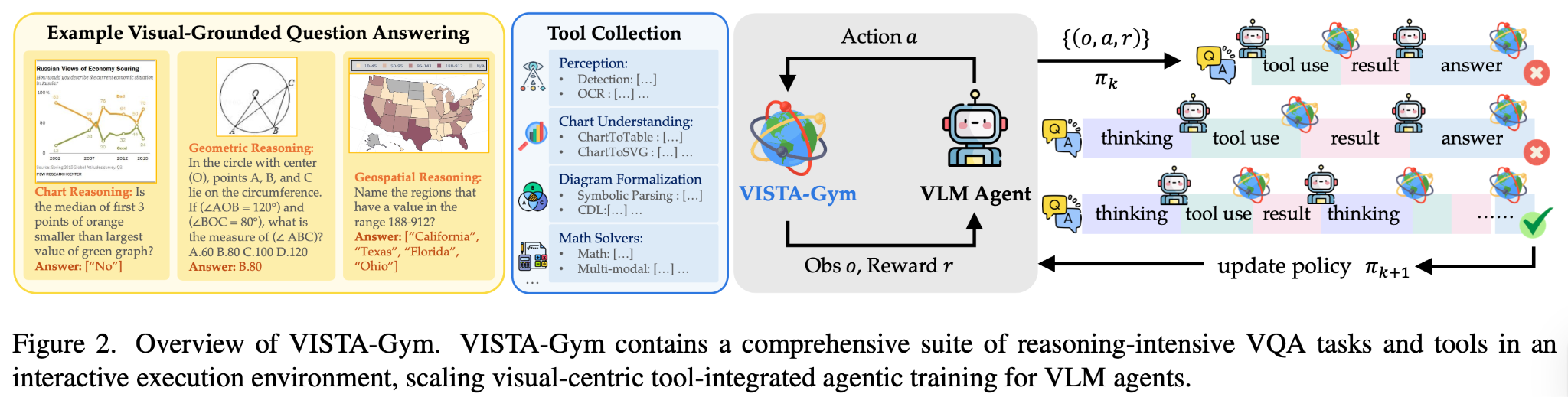
VISTA-Gym: A Scalable Training Ground
To bridge this gap, we built VISTA-Gym, a high-throughput RL environment compatible with Ray and Gymnasium APIs.
Key features of VISTA-Gym include:
- Diverse tasks: covers 7 distinct reasoning domains (e.g., Charts, Geometry, Maps) across 13 datasets.
- Extensive toolset: provides a unified interface for 26 visual and symbolic tools, including Grounding DINO, EasyOCR, and math solvers.
- Scalable infrastructure: supports asynchronous training with compute-intensive VLMs hosted as persistent microservices to minimize latency.
Training VISTA-R1: From SFT to Agentic RL
VISTA-R1 is trained using a two-stage recipe designed to foster a “Think-Before-You-Act” methodology.
Stage 1: Warm-up with Behavioral Cloning
We first use supervised fine-tuning (SFT) to teach the model the basic syntax of tool usage. We synthesized expert trajectories using GPT-5 and densified the reasoning steps using Qwen3-VL-Thinking to create high-quality training data.
Stage 2: Online Reinforcement Learning (GRPO)
The crucial performance leap comes from online RL. We employ Group Relative Policy Optimization (GRPO), which normalizes advantages within a group of outputs to reduce variance.
Our reward function is designed to be sparse yet strictly format-aware:
- Repetition penalty: heavily penalizes repetitive text generation.
- Format reward: ensures correct XML tag structure (, <tool_call>).
- Correctness reward: rewarded only if the final answer matches the ground truth and the format is valid.
Performance
We evaluated VISTA-R1 against top-tier proprietary and open-source models across 5 in-distribution and 6 out-of-distribution (OOD) benchmarks.
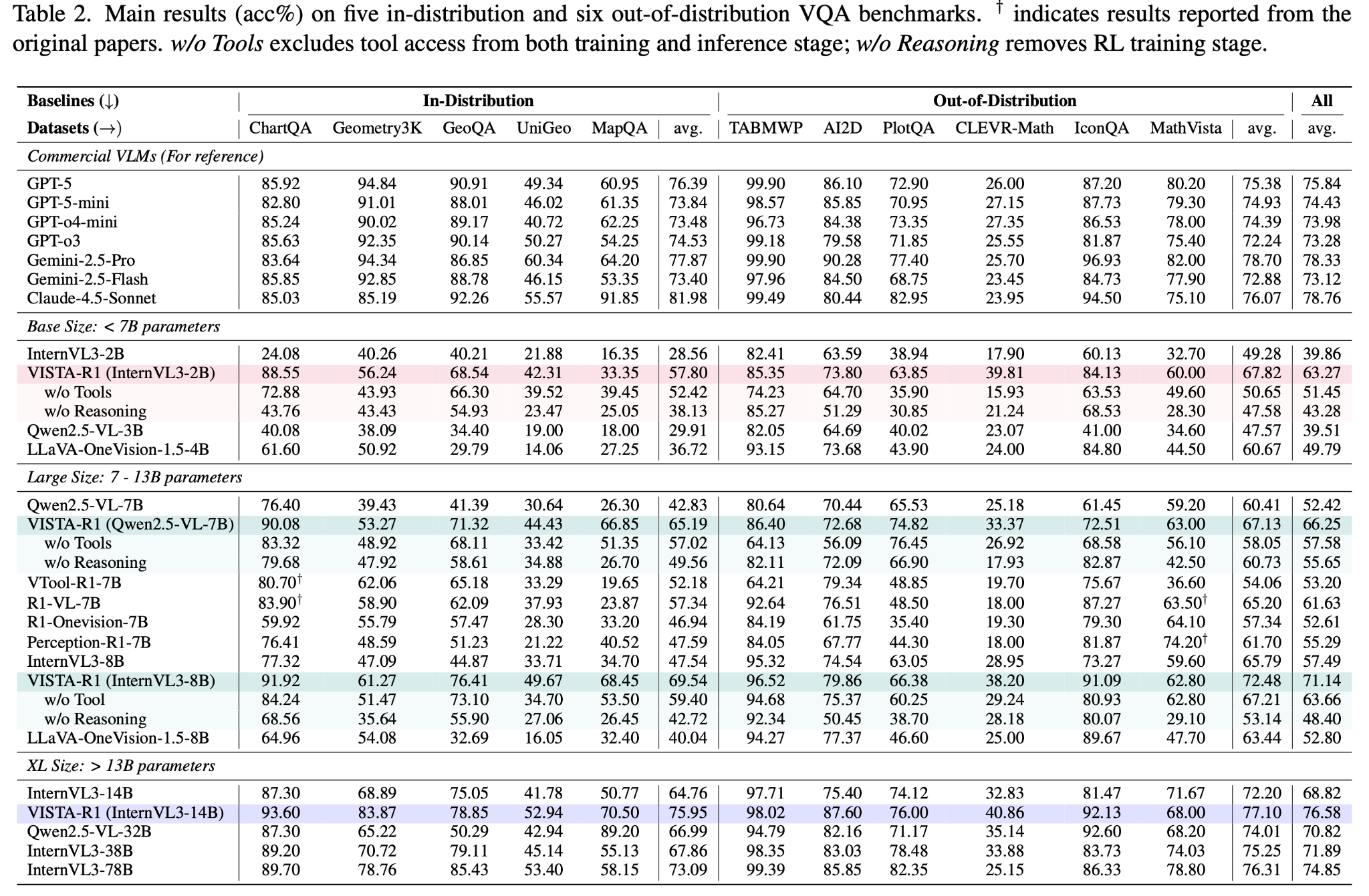
Key findings:
- SOTA performance: VISTA-R1-8B surpasses InternVL3-8B and other baselines by margins of up to 18.72%.
- Out-of-distribution generalization: strong performance on datasets it was never trained on suggests general reasoning skills.
- Efficiency: the 8B model rivals the performance of much larger 38B parameter models.
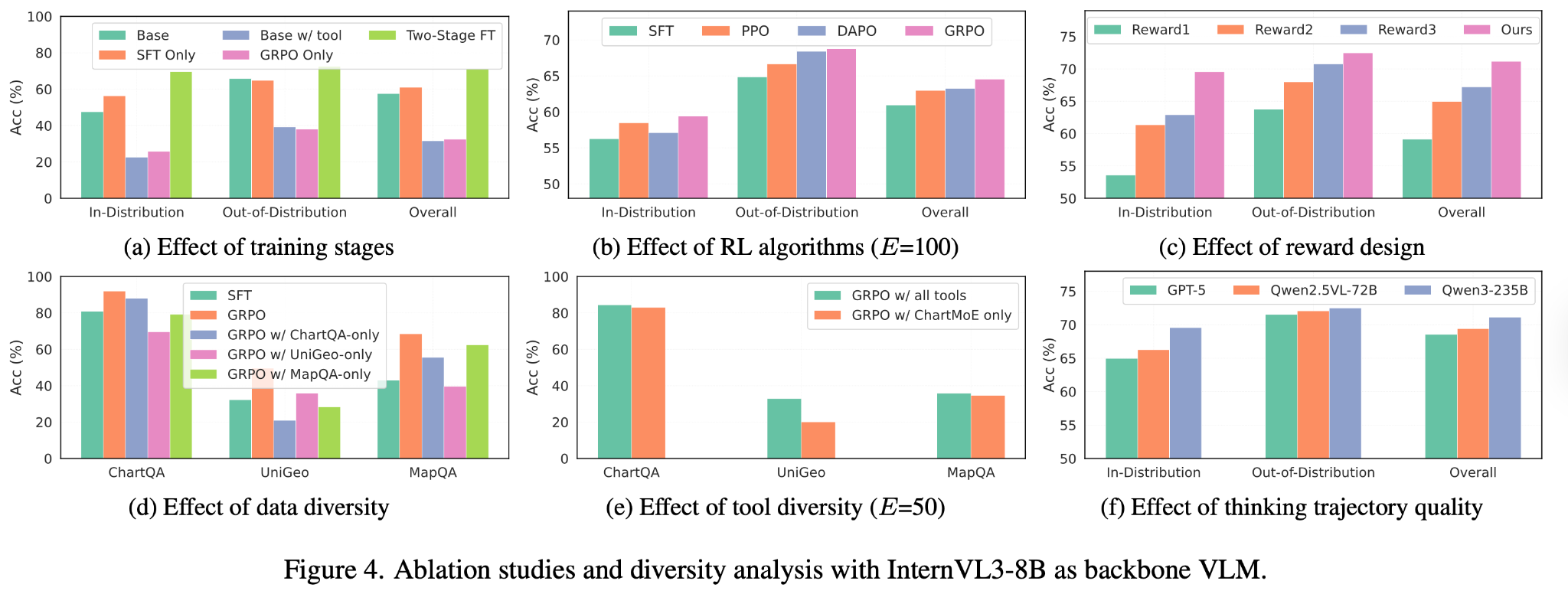
Ablation: The Power of RL
Our ablation studies confirm that RL is the primary driver of these gains. While SFT provides a +3.46% improvement, adding RL contributes a massive +10.19% gain, showing the model learns to self-correct and coordinate tools through trial and error.
Conclusion
VISTA-Gym and VISTA-R1 demonstrate that equipping VLMs with tools requires more than just API access—it requires a fundamental shift in training methodology towards Agentic RL. By scaling up the environment and refining the reward mechanism, we can unlock models that truly “think” with images.
The code and environment are available now for the community to build upon.
Resources
- Paper: arXiv:2511.19773
- Code & data: Lucanyc/VISTA-Gym