
Eigen-1: Toward Efficient and Coherent Scientific Reasoning
Introduction
Large language models (LLMs) have made remarkable progress in scientific reasoning, yet two persistent bottlenecks remain.
First, explicit retrieval interrupts reasoning, forcing models to pause mid-thought to call external tools — a phenomenon we term the Tool Tax.
Second, multi-agent workflows often average all solutions equally, diluting strong reasoning with weaker paths.
Eigen-1 addresses both with a unified framework combining implicit retrieval and hierarchical collaboration.
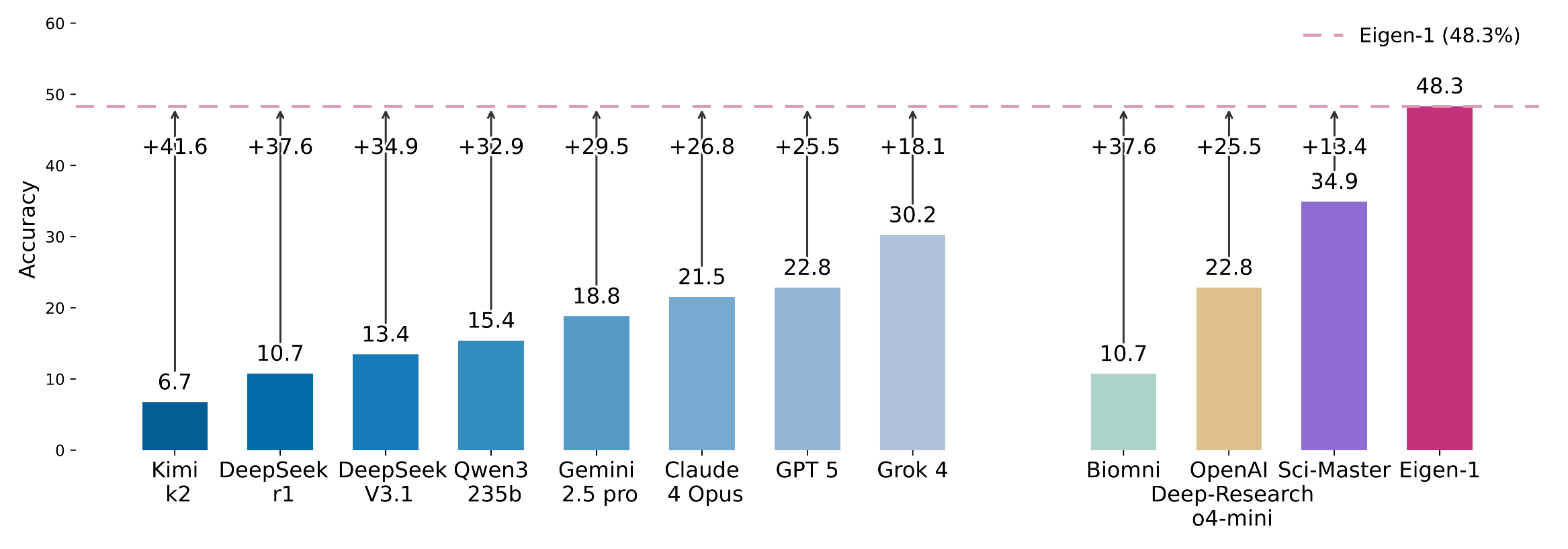
It achieves 48.3 % accuracy on Humanity’s Last Exam (HLE) Bio/Chem Gold — the highest reported result — while cutting token usage by 53.5 % and agent steps by 43.7 %.
The system delivers faster, more coherent reasoning across scientific domains, validated also on SuperGPQA and TRQA.
Code and resources: https://github.com/tangxiangru/Eigen-1
Why Scientific Reasoning Needs Implicit Retrieval
When LLMs confront expert-level problems (e.g., biochemistry or genetics), factual recall alone fails.
Existing retrieval-augmented systems require explicit tool calls: the model stops, queries a database, then rebuilds its context.
This stop-and-resume cycle introduces the Tool Tax — lost tokens, latency, and broken logical flow.
Our analysis on HLE Bio/Chem revealed that knowledge gaps and reasoning failures co-occur in 85 % of cases, showing that knowledge integration and reasoning continuity must be solved together.
Architecture Overview
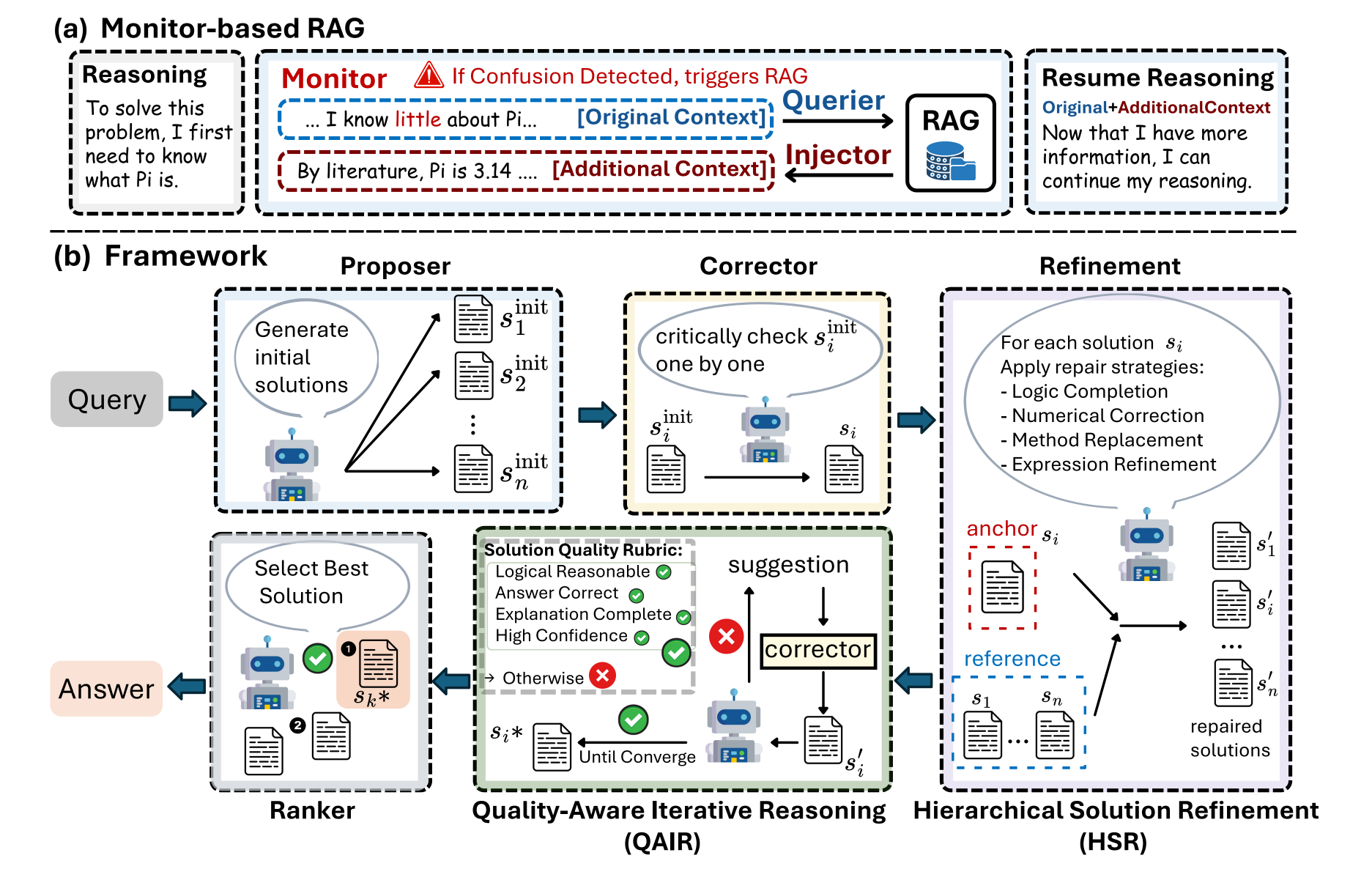
Eigen-1 is built atop SGLang-compatible serving infrastructure and integrates three core modules:
1. Monitor-Based RAG (Monitor + Querier + Injector)
A token-level retrieval system that detects semantic uncertainty in real time and injects external evidence without pausing reasoning.
- Monitor detects when the model is unsure.
- Querier generates minimal, precise queries.
- Injector compresses and weaves the retrieved evidence back into the reasoning stream.
Result: no context suspension, no Tool Tax.
2. Hierarchical Solution Refinement (HSR)
Instead of democratic averaging, Eigen-1 introduces anchor–reference refinement.
Each candidate solution temporarily acts as an anchor, improved by targeted repairs from peer references — fixing logic gaps, numerical slips, or methodological flaws.
3. Quality-Aware Iterative Reasoning (QAIR)
A dynamic evaluation loop scoring logic, correctness, and explanation on a 0–5 scale.
Low-scoring solutions trigger automatic corrections until convergence, ensuring adaptive improvement without endless iterations.
Together, these modules form a continuous reasoning-retrieval loop that keeps thought coherence while improving factual precision.
Example: Population Genetics and Haplotype Counting
Traditional LLMs often misremember formulas (e.g., confusing θ \= 2 Nₑ μ with θ \= 4 Nₑ μ) or fail to reintegrate retrieved facts.
Eigen-1’s Monitor-Based RAG automatically detects such uncertainty, retrieves the correct relation, and re-injects it seamlessly — solving the problem in one coherent reasoning stream.
In another example, a haplotype-counting task across F₁ → F₃ generations required understanding recombination constraints.
Eigen-1’s Monitor triggered retrieval (“maximum number of recombination change-points”) and injected key facts (“at most one breakpoint per gamete”).
The reasoning then converged correctly on 30 unique haplotypes
Experimental Results
| Benchmark | Accuracy (%) ↑ | Token Usage ↓ | Step Count ↓ | Base Model |
|---|---|---|---|---|
| HLE Bio/Chem Gold | 48.3 | −53.5 % | −43.7 % | DeepSeek V3.1 |
| SuperGPQA (Biology Hard) | 69.6 | — | — | DeepSeek V3.1 |
| TRQA (Literature) | 54.7 | — | — | DeepSeek V3.1 |
- Surpasses the strongest agent baseline (SciMaster) by +13.4 points.
- Outperforms GPT-5 and Claude Opus 4.1 by >18 points on HLE Bio/Chem.
- Under Pass@5, reaches 79.1 % accuracy.
These results confirm that implicit augmentation + hierarchical refinement enhance both accuracy and efficiency
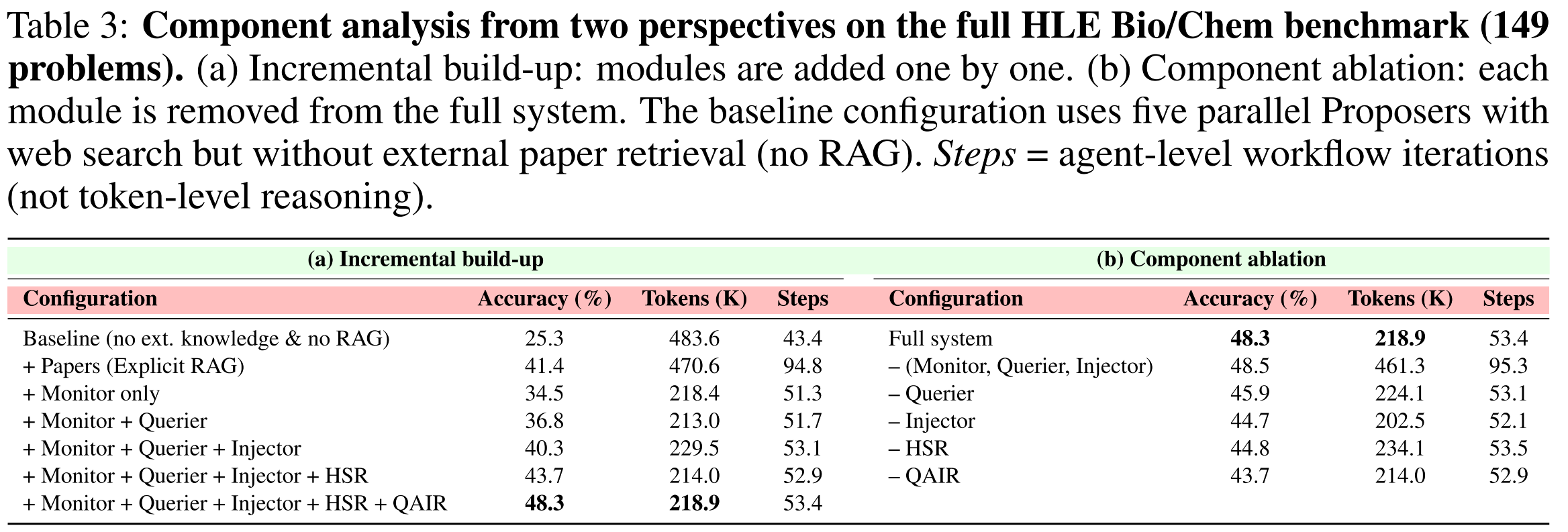
Component Ablation Summary
| Configuration | Accuracy (%) | Tokens (K) | Steps |
|---|---|---|---|
| Baseline (no RAG) | 25.3 | 483.6 | 43.4 |
| Explicit RAG | 41.4 | 470.6 | 94.8 |
| + Monitor + Querier + Injector | 40.3 | 229.5 | 53.1 |
| + HSR + QAIR (Full Eigen-1) | 48.3 | 218.9 | 53.4 |
Key insight: Explicit retrieval doubles reasoning steps without proportional benefit.
Eigen-1 recovers reasoning coherence while maintaining speed and quality.
Error and Diversity Analysis
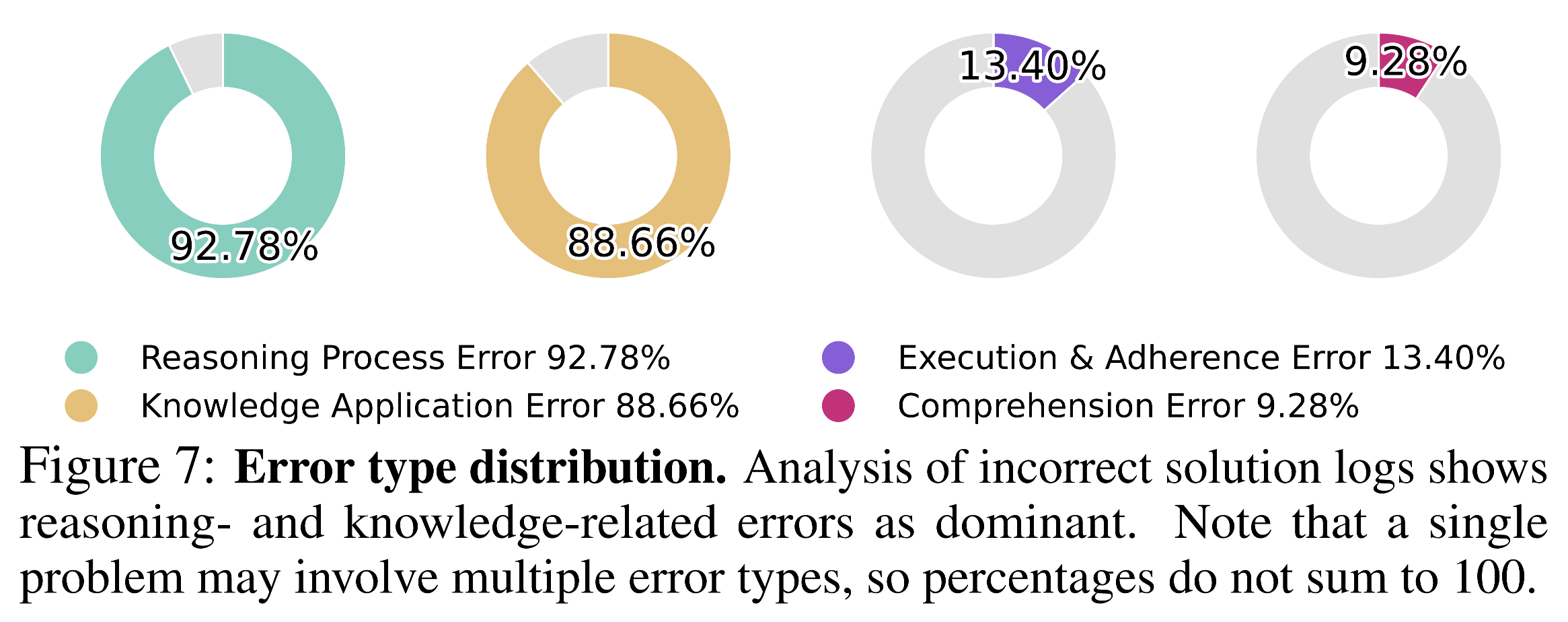
- 92.8 % of errors \= reasoning process failures
- 88.7 % \= knowledge application errors
These overlap heavily, underscoring the need for implicit knowledge integration.
Furthermore, analysis of multi-agent diversity shows that
- Retrieval-heavy tasks benefit from diverse solutions,
- Reasoning-heavy tasks benefit from consensus.
Eigen-1 adapts between both via QAIR’s dynamic feedback loop.
Implications and Future Work
Eigen-1 demonstrates that architectural design, not scale alone, drives progress in scientific reasoning.
By embedding retrieval into continuous generation and structuring multi-agent collaboration hierarchically, the system achieves both efficiency and transparency.
Future directions include:
- Extending Monitor-based RAG to multimodal domains (video or graphs),
- Integrating Eigen-1 into scientific workflow assistants,
- Exploring reinforcement-based adaptive retrieval policies.
Acknowledgments
Eigen-1 was developed by the Eigen AI Research Team in collaboration with researchers from Yale University, Shanghai Jiao Tong University, Fudan University, UCLA, Oxford, and Shanghai AI Lab.
Code and resources: https://github.com/tangxiangru/Eigen-1