
Day 0 Support of Serving OpenAI GPT-OSS on Hopper and Blackwell GPUs with Free Online Playground
In this blog, we're excited to achieve day 0 support for the serving of OpenAI’s GPT-OSS-120B and GPT-OSS-20B on Hopper/Blackwell GPUs in collaboration with the SGLang team. We also introduce a free online playground featuring both web and API access to the GPT-OSS-120B model (chat.eigenai.com) in partnership with Yotta Labs. Major performance optimizations are already in the pipeline, and we expect to offer even faster, smarter, and more scalable services in the days ahead.
Introduction of GPT-OSS Architecture
GPT-OSS is a newly released open-source large language model (LLM) from OpenAI designed for the efficient deployment of reasoning tasks. OpenAI open-sourced two versions of GPT-OSS: GPT-OSS-120B and GPT-OSS-20B.
- GPT-OSS-120B: for production, general purpose, high reasoning use cases (117B parameters)
- GPT-OSS-20B: for lower latency, and local or specialized use cases (21B parameters)
Figure 1 illustrates the architectural details.
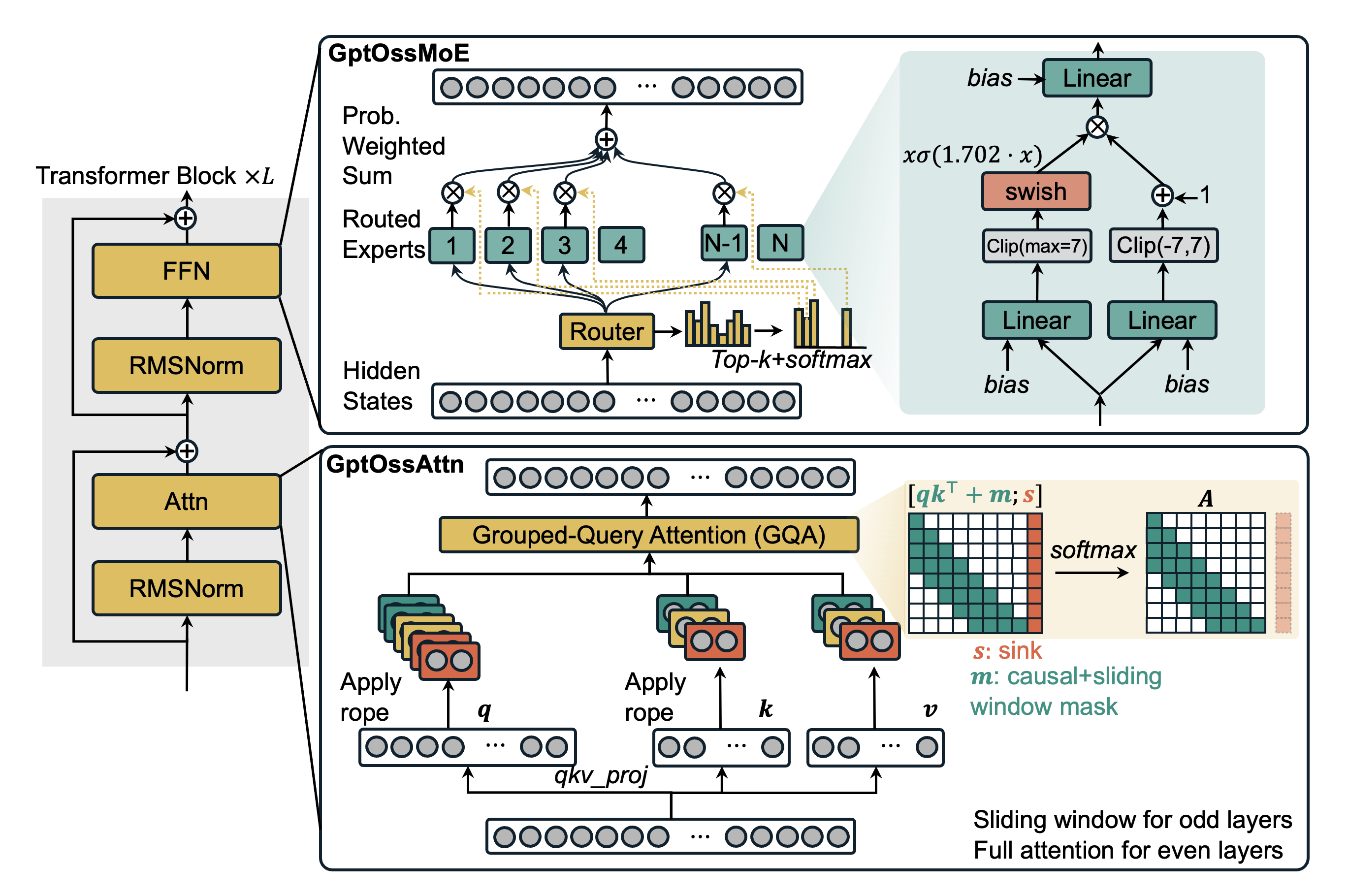
Figure 1. Illustration of GPT-OSS architecture. GptOssMoE layers and GptOssAttn (sinked sliding window grouped-query attention) layers.
GptOssAttn
GPT-OSS introduces a novel attention mechanism that interleaves sliding window attention and full attention. Specifically, odd-numbered layers use sliding window grouped-query attention (GQA) with a window size of 128, and even layers use full attention. All attention layers include bias terms in the linear projection layers (queries, keys, values, and output). A distinctive sinked attention mechanism is applied: for each attention head, a learnable scalar parameter (referred to as the sink) is appended as the last column of the attention score matrix S prior to softmax. After softmax computation, the sink column is detached, yielding a standard square attention matrix A. This operation is mathematically equivalent to modifying the softmax denominator with an additional exponential term.
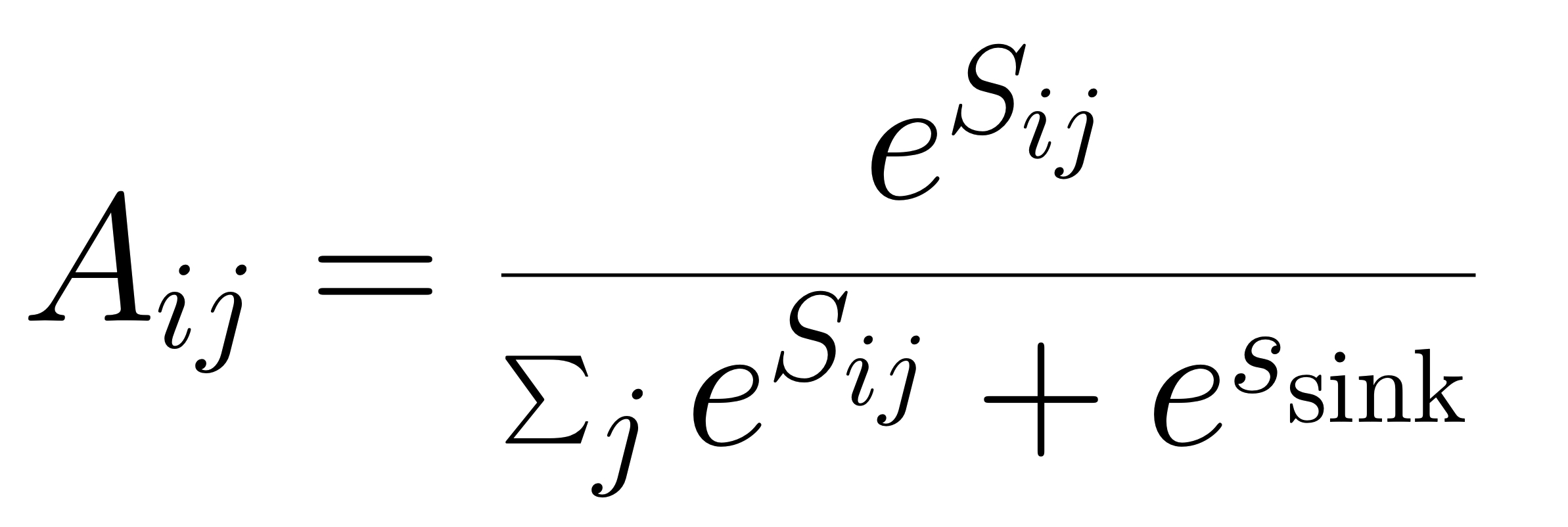
Why Attention Sinks? Incorporating a single learnable parameter into each attention head allows the model to disregard all tokens as necessary. By introducing a sink, attention is diverted from other tokens, thereby restricting the propagation of information (and potential noise), which yields more consistent embeddings. This stability is particularly vital for the effective operation of sliding window attention. The model card for OpenAI's GPT-OSS-20B details this attention sink mechanism, explicitly linking the design to prior investigations, namely StreamingLLM [1] and SpAtten [2].
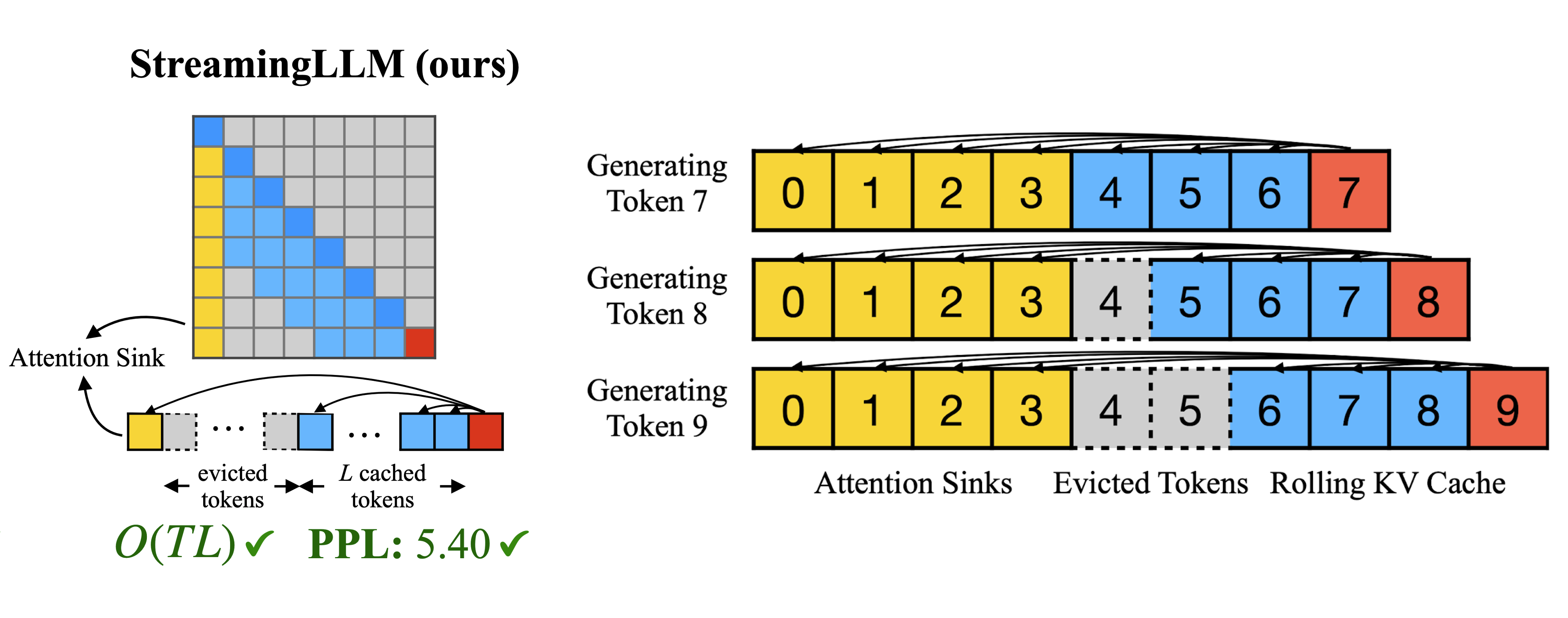
Figure 2. Within MIT-HAN-Lab's StreamingLLM [1], the initial "sink" tokens are retained in the cache, facilitating generation of unlimited length by adhering to the model's inherent attention dynamics.
The methodology employed in StreamingLLM learns a full token embedding that is capable of varying interactions with each query (as illustrated in Figure 2), whereas OpenAI implements a solitary learnable value functioning as a universal release mechanism. Both strategies effectively address the core challenge: providing an outlet for attention when no substantive focus is required.
Figure 3. Initial tokens are always kept in SpAtten [2].
A similar phenomenon has been observed in BERT, where a surprisingly large amount of attention focuses on the delimiter token [SEP] and periods. Our work SpAtten [2] in 2021, which pioneered attention score-based KV Cache pruning and quantization of attention, also found that GPT-2 preserved its initial token, as shown in Figure 3.
The attention sink mechanism discovered has since been adopted across the industry, appearing in production systems like OpenAI's models and inspiring new research directions in quantization and model optimization.
GptOssMoE
For Mixture-of-Experts (MoE) layers, each token selects the top-4 experts based on router scores from 128 (for 120B) or 32 (for 20B) experts. The expert adopts SwigLU activation, and three linear layers, including gate, up, and down projections, all have bias terms enabled. The gate branch employs a Swish activation function with β = 1.702, and the up branch is added by 1 and multiplied with the gate output. To ensure numerical stability:
- The gate pre-activation is clipped at a maximum value of 7 before applying Swish.
- The up branch is clipped to the range [−7, 7] before the +1 shift.
The MoE computation is summarized as:
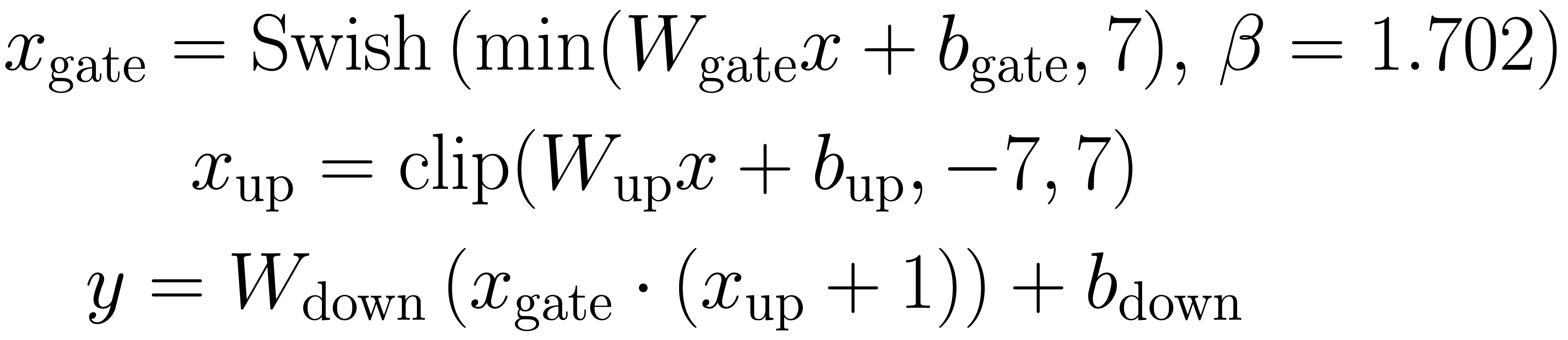
The outputs of the top-k selected experts will be summed up with the softmax-normalized router weights.
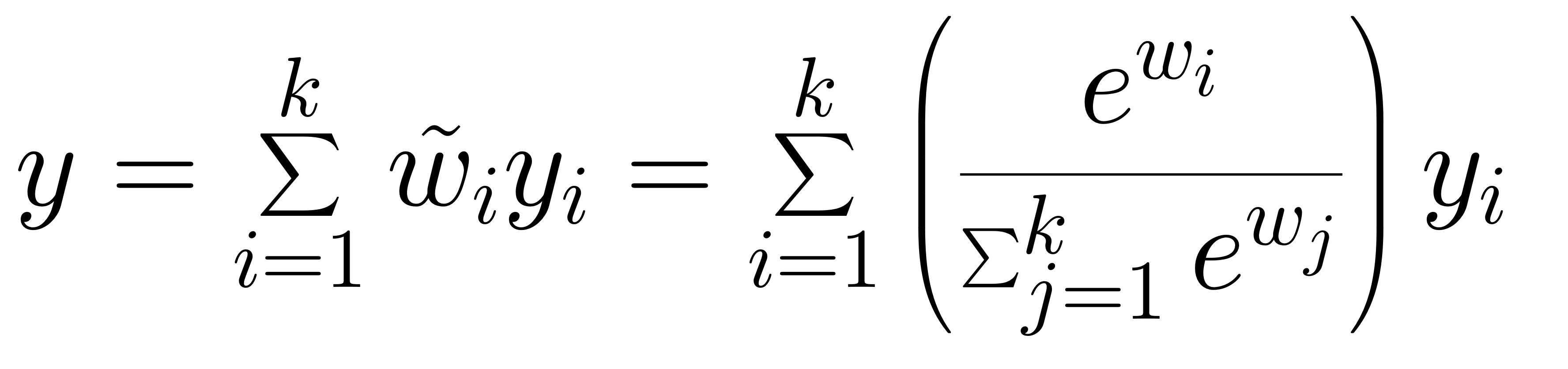
Try Local GPT-OSS Serving on Hopper/Blackwell GPUs
Please follow the instructions here to set up a ready-to-use container to try out GPT-OSS serving.
Introducing the Eigen AI Playground
We’re thrilled to announce the launch of the Eigen AI Playground, built in partnership with Yotta Labs – a free online platform where anyone can experience the power of OpenAI’s GPT-OSS-120B model right in their browser: chat.eigenai.com. This platform is well optimized for performance and includes comprehensive, reproducible deployment guides, enabling users to integrate these advancements into their projects with ease. This initiative reflects our broader vision to make the transformative power of AI accessible globally, fostering innovation across industries and communities.
Explore now on the web:
The web interface offers an intuitive and smooth chat experience with GPT-OSS-120B:
Integrate via API:
For developers or advanced users, we also provide a simple API that allows you to integrate GPT-OSS-120B directly into your applications for free.
# First install: pip install openai
import openai
client = openai.OpenAI(
api_key="xxx",
base_url="https://gateway.eigenai.com/inference/public/v1"
)
response = client.chat.completions.create(
model="OpenAI/GPT-OSS-120B",
messages=[
{"role": "assistant", "content": "what can i help you?"},
{"role": "user", "content": "test"},
],
temperature=0.6,
max_tokens=8192,
stream=False,
)
# Print the completion result
print(response.choices[0].message.content)Acknowledgments
We would like to express our heartfelt gratitude to the following teams and collaborators:
- Eigen AI Team & Community – Jinglei Cheng, Jiaqi Gu, Yipin Guo, Di Jin, Yilian Uill Liu, Shuqing Luo, Zilin Shen, Ryan Wang, Wei-Chen Wang, Genghan Zhang, and many others.
- SGLang Community
- Yotta Labs
- Innomatrix
Further Reading
- At Eigen AI, we’re on a mission to make sure the AI revolution doesn’t leave anyone behind. | Eigen AI
- SGLang GitHub Repository
- EigenAI Labs Huggingface Repository with GPT-OSS BF16 Checkpoints
- How Attention Sinks Keep Language Models Stable
- OpenAI GPT-OSS model card
References
[1] Xiao, G., Tian, Y., Chen, B., Han, S., & Lewis, M., “Efficient Streaming Language Models with Attention Sinks,” ICLR 2024.
[2] Wang, H., Zhang, Z., & Han, S., “SpAtten: Efficient Sparse Attention Architecture with Cascade Token and Head Pruning,” HPCA 2021.