
Introduction
We are excited to introduce WorkForceAgent-R1, a new open-source framework that brings reinforcement learning–driven reasoning to LLM-based web agents.
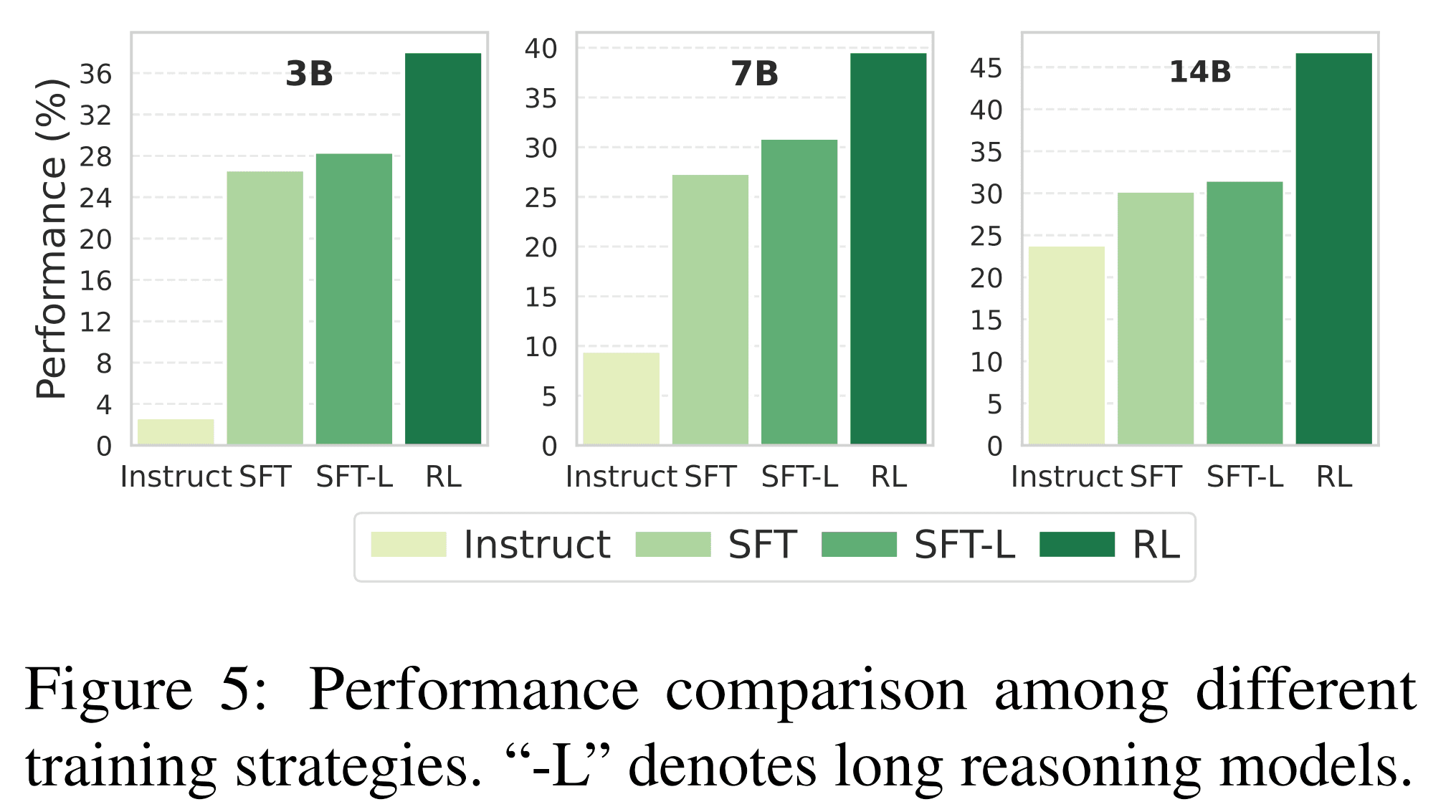
WorkForceAgent-R1 enhances the reasoning and planning capabilities of open-source agents for enterprise web automation, achieving a 10.26 – 16.59 % improvement over supervised-fine-tuned baselines on the WorkArena benchmark.
Trained through a rule-based R1-style reinforcement learning scheme, it teaches agents to perform accurate single-step reasoning without relying on expensive expert demonstrations or reasoning annotations. By combining reward-structured reinforcement learning with flexible prompt templates, WorkForceAgent-R1 achieves performance competitive with commercial systems such as GPT-4o and GPT-4.1-mini, while remaining fully reproducible and cost-efficient.
📄 Paper on arXiv 💻 GitHub Repository

Why Reinforcement Learning for Web Agents?
Modern workplaces increasingly depend on LLM-driven web agents to automate tasks such as data entry, catalog ordering, and dashboard analysis.
Yet, traditional supervised fine-tuning (SFT) approaches often fall short: they optimize surface-level behaviors instead of genuine reasoning, leading to agents that mimic patterns without understanding dynamic web contexts.
Web environments pose additional challenges—noisy HTML structures, dynamic interfaces, and non-standard element identifiers—that demand adaptive reasoning and precise single-step planning.
While multi-turn reasoning can be computationally expensive, a robust single-step reasoning policy offers a scalable and efficient alternative.
WorkForceAgent-R1 addresses these gaps through rule-based reinforcement learning that rewards accurate reasoning, format adherence, and action correctness.
This approach incentivizes agents not merely to “act,” but to think before they act—an essential skill for real-world enterprise automation.
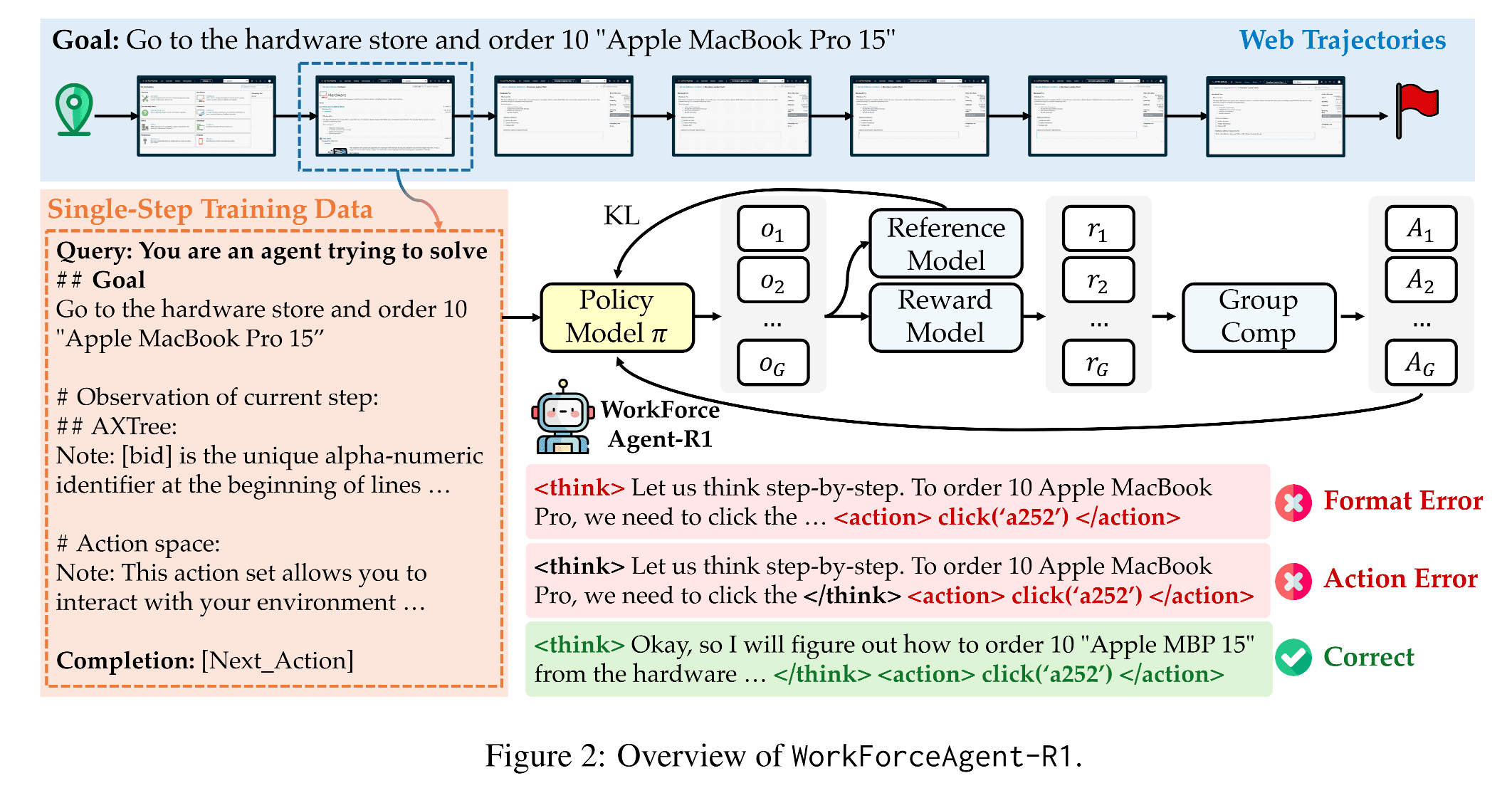
Architecture
WorkForceAgent-R1 builds upon a hybrid pipeline that integrates Supervised Fine-Tuning (SFT) and Group-Relative Policy Optimization (GRPO), enabling step-wise reasoning reinforcement.
At its core lies a structured prompting template that explicitly separates reasoning and actions using:
<think> ... intermediate reasoning ... </think><action> ... executable operation ... </action>
This format helps the model form interpretable reasoning chains while maintaining execution-ready outputs.
The system architecture (below) decomposes training into three stages:
- Behavior Cloning (SFT) — builds a baseline web policy from heuristic trajectories.
- Rule-Based Reinforcement Learning (GRPO) — iteratively refines the policy with structured rewards.
- Reward Evaluation Pipeline — measures reasoning correctness via format, action, and penalty rewards.
Reward Function Design
The progressive reward system contains three tiers:
- Format Reward (Rf) — encourages correct tag structure (
<think>/<action>). - Success Reward (Rs) — validates action type and parameter accuracy.
- Penalty Reward (Rp) — discourages over-generation and reward hacking.
This balanced combination enables the agent to develop stable reasoning trajectories without external supervision.
Model Support
WorkForceAgent-R1 supports multiple open-source LLM backbones, including:
- Qwen 2.5-3B / 7B / 14B Instruct
- Qwen 3-8B
- LLaMA 3.1-8B Instruct
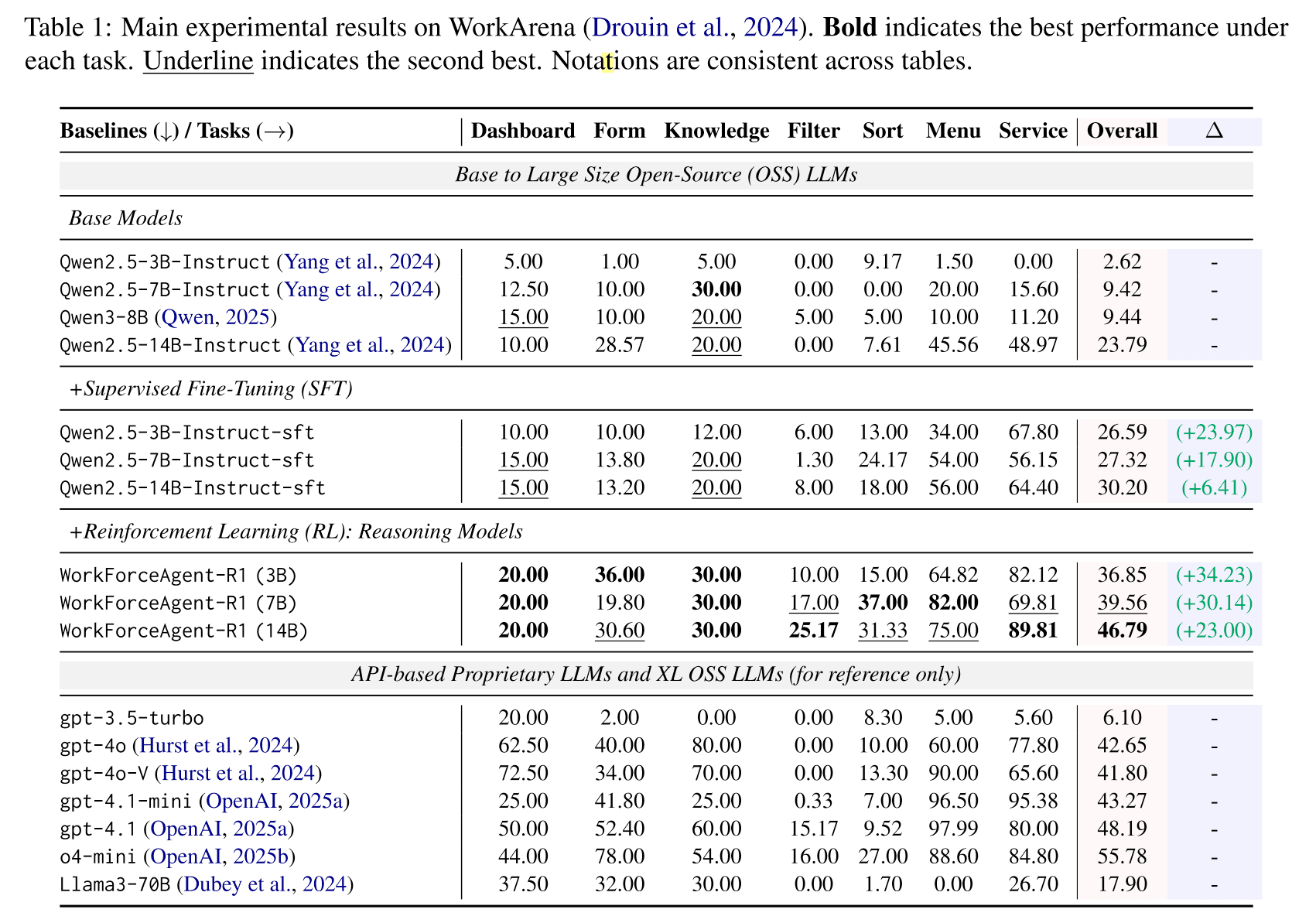
These variants demonstrate consistent gains under RL-training, with the 14B version even surpassing GPT-4o on overall task success rates in WorkArena.
Performance Benchmark
WorkForceAgent-R1 was evaluated on the WorkArena benchmark, covering seven categories such as Forms, Dashboards, Knowledge Bases, and Service Catalogs.
The RL-trained models achieve up to 46.79 % overall accuracy, outperforming all open-source baselines and matching commercial LLMs on multiple sub-tasks.
| Model | Avg Gain vs SFT | Key Highlight |
|---|---|---|
| WorkForceAgent-R1 (3B) | +34.2% | Improved reasoning accuracy |
| WorkForceAgent-R1 (7B) | +30.1% | Balanced task performance |
| WorkForceAgent-R1 (14B) | +23.0% | Surpassed GPT-4o in success rate |
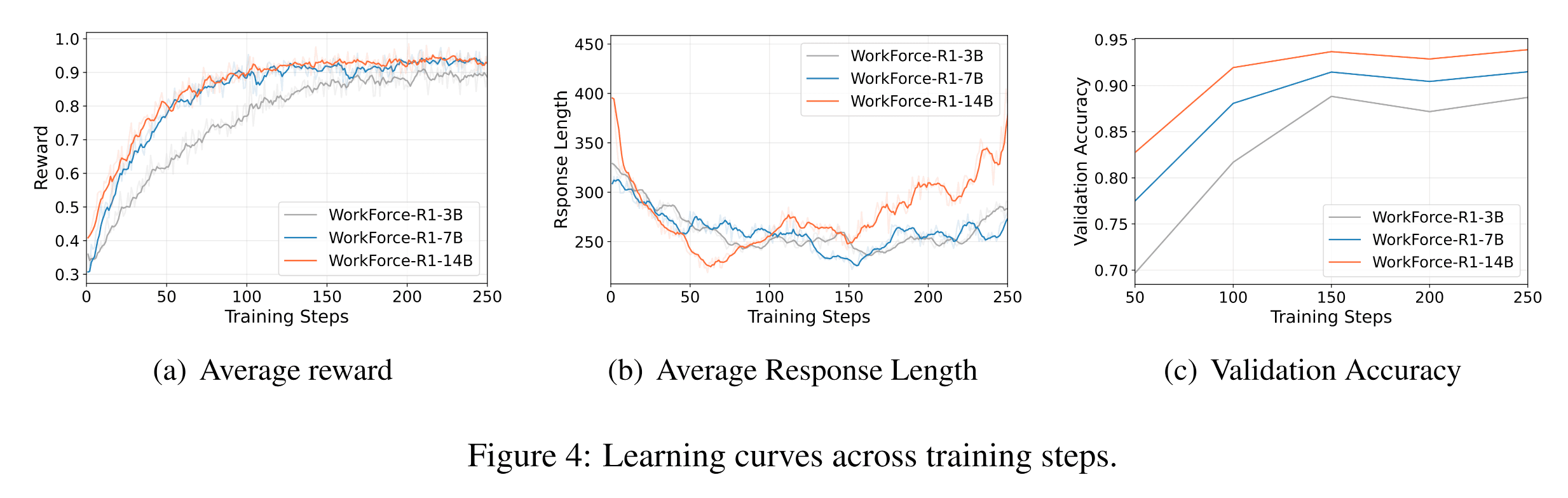
Training Insights
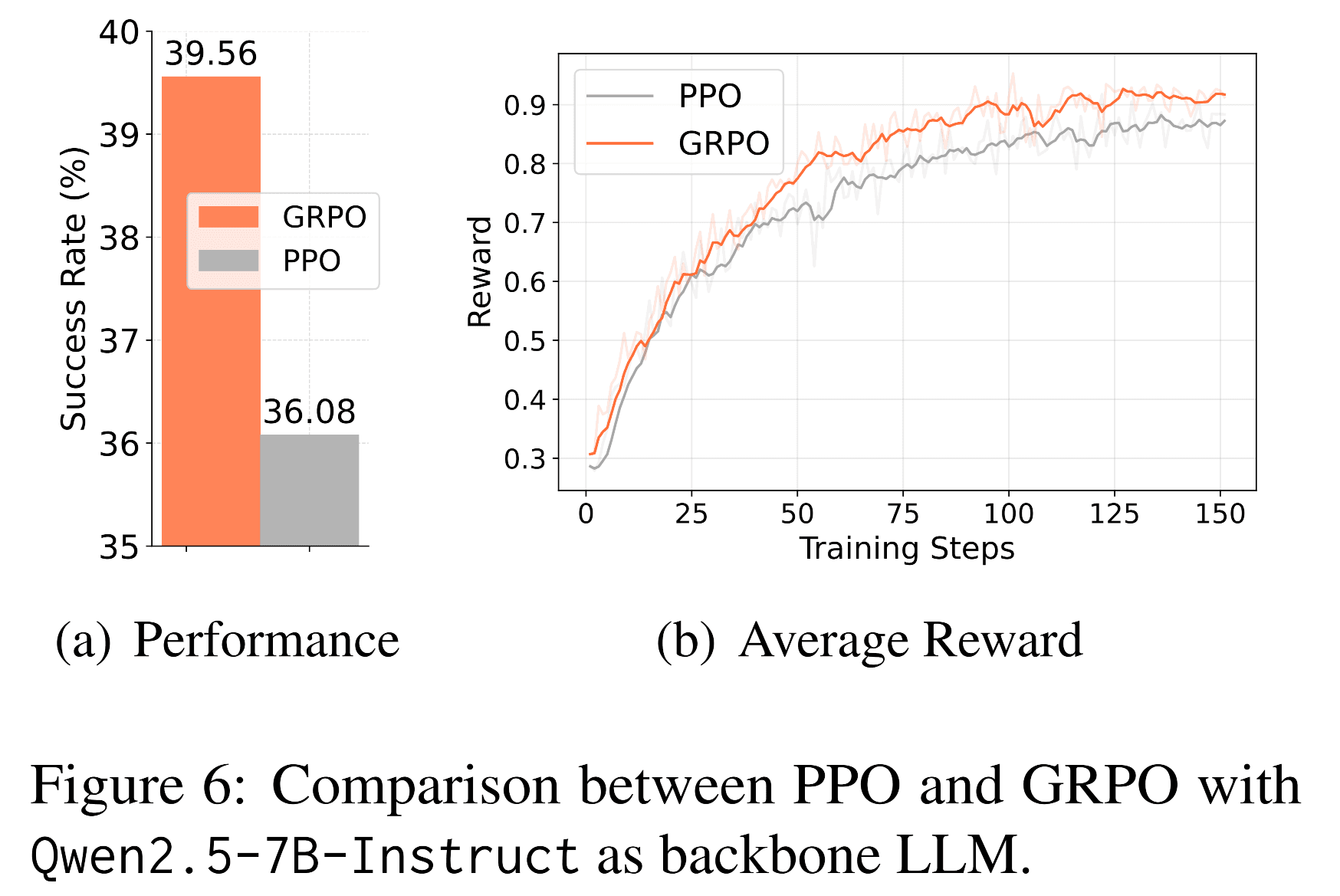
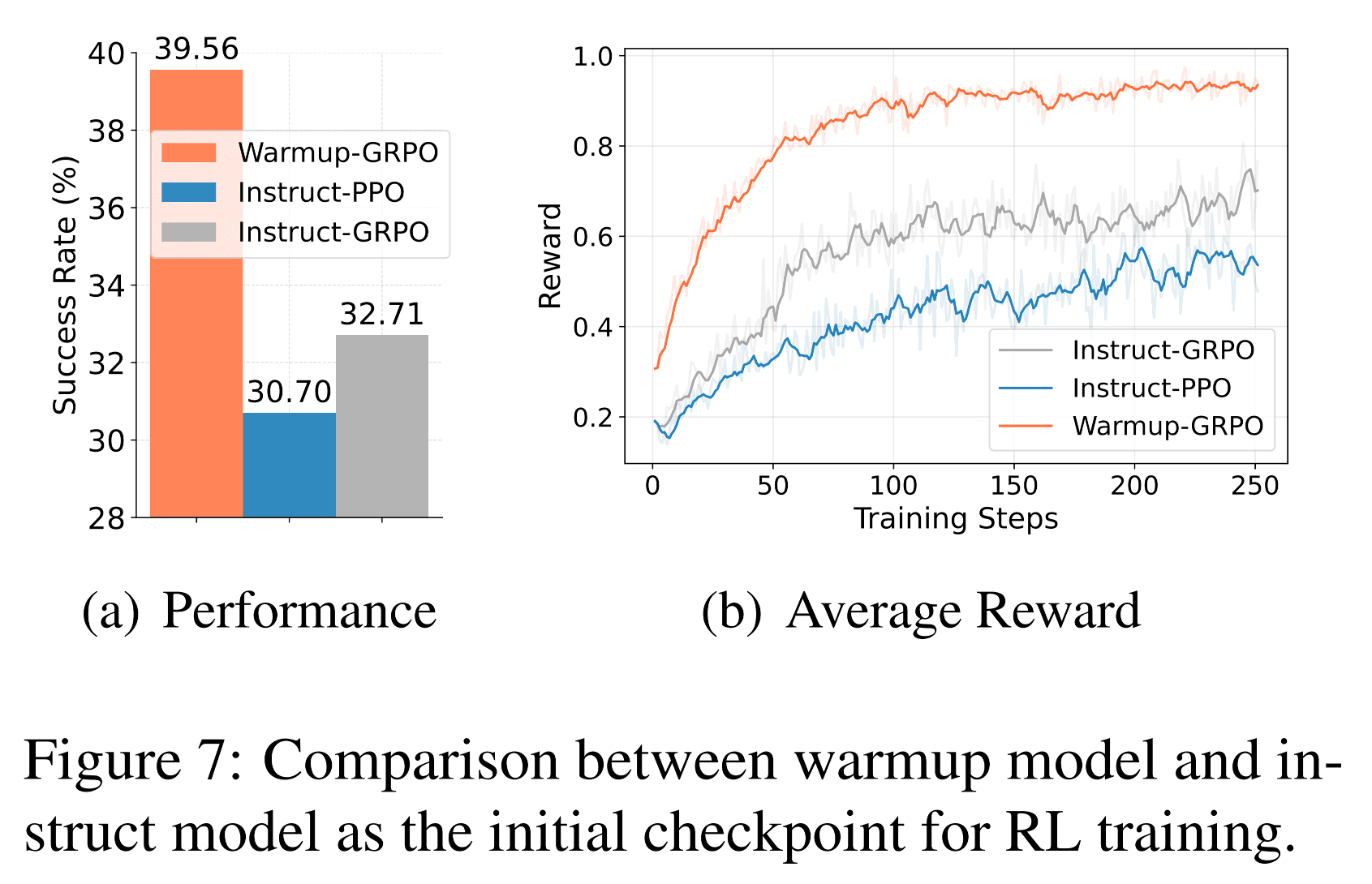
1. Stable Reward Growth — Reinforcement learning produces consistent reward and validation accuracy improvements.
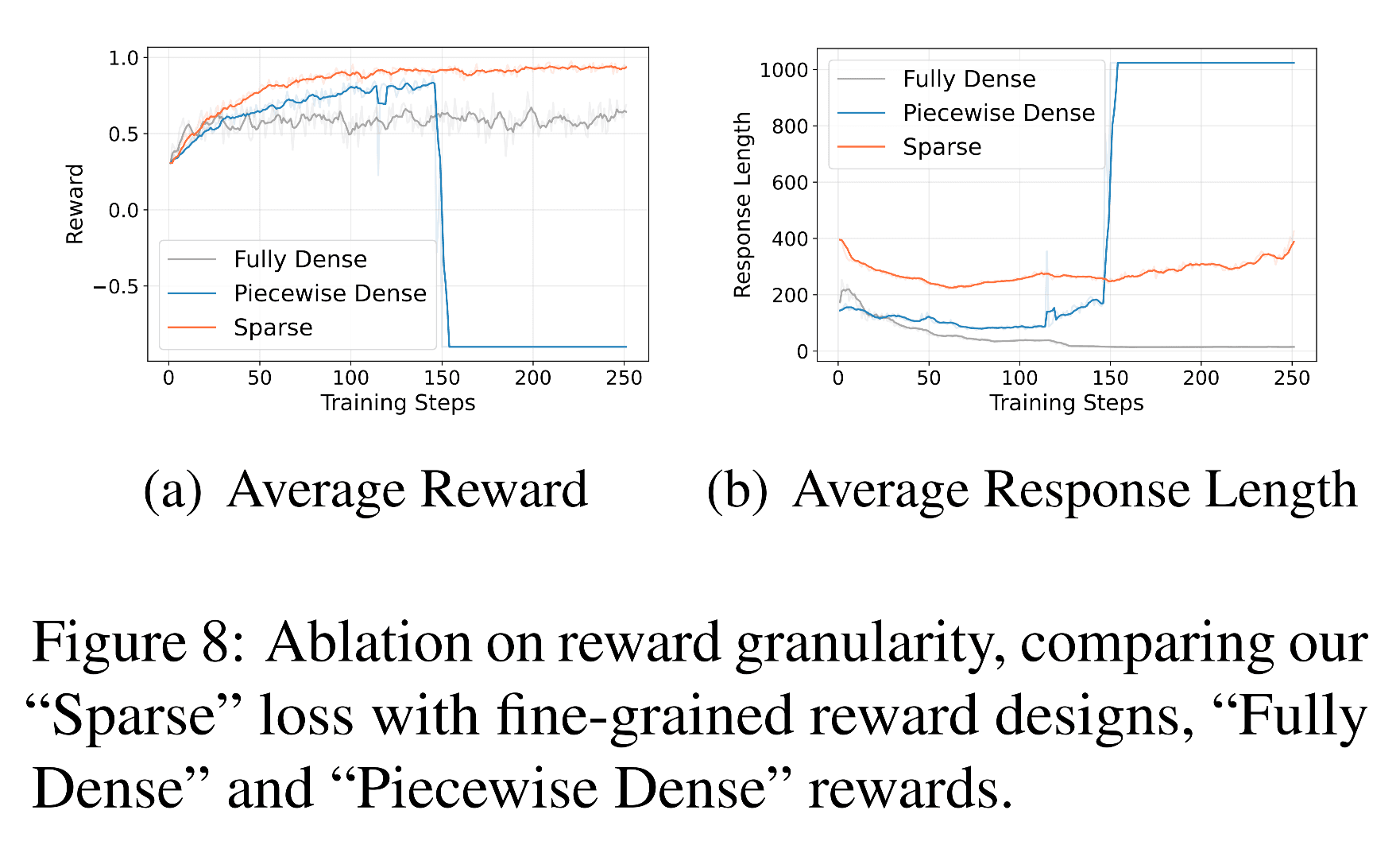
2. Longer Reasoning Chains — Larger models show emergent reasoning, with response lengths stabilizing then increasing as logical depth improves.
3. Reward Granularity Effects — Sparse reward signals outperform dense ones, preventing “reward hacking” behaviors.
Roadmap & Ecosystem
Our goal is to build an open ecosystem for reasoning-enhanced web agents.
Future directions include:
- Expanding support for new enterprise platforms beyond ServiceNow
- Integrating multimodal observation (vision + text)
- Developing R2-style hierarchical reasoning RL
- Collaborating with BrowserGym and FastVideo teams for unified agent evaluation
We invite the community to join us in shaping the next generation of intelligent, self-improving web agents.
Acknowledgment
WorkForceAgent-R1 was developed by the WorkForceAgent Research Team in collaboration with researchers from Georgia Institute of Technology and the Massachusetts Institute of Technology. The project also benefited from contributions by open-source collaborators who supported large-scale training and evaluation.